📝 Paper Summary
Modularized RAG pipeline
Federated Learning
GPT-FedRec combines federated hybrid retrieval (merging ID-based user patterns with text-based item semantics) and LLM-based re-ranking to improve recommendations in data-sparse, heterogeneous federated settings.
Core Problem
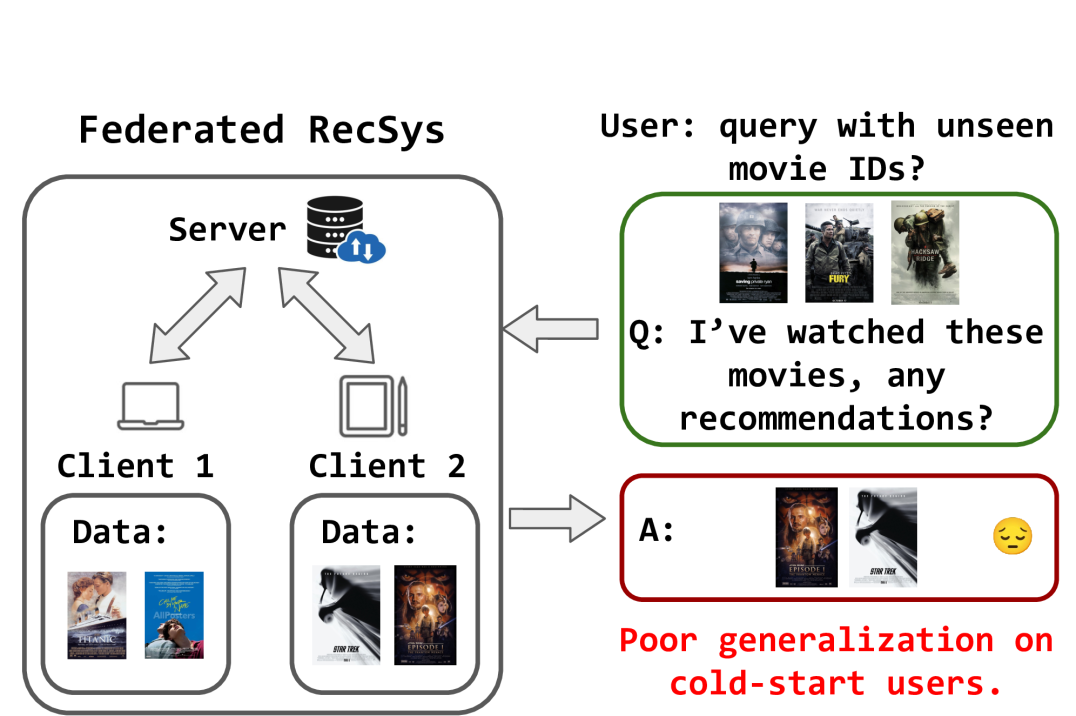
Traditional Federated Recommendation (FR) systems using discrete IDs struggle with data sparsity and heterogeneity (non-i.i.d. data), often failing to generalize to cold-start users or unseen items.
Why it matters:
- Privacy regulations (e.g., GDPR) necessitate federated approaches, but client data is often too sparse to train effective local ID-based models
- Heterogeneity means clients may have disjoint item sets; a model trained on Client A's IDs cannot recommend Client B's items to a new user effectively
- Directly using LLMs for recommendation is computationally expensive and prone to hallucinating non-existent items
Concrete Example:
In a movie recommendation scenario, Client 1 has 'love, romantic movies' and Client 2 has 'sci-fi, action movies'. A new user enters with a history of 'war, action movies' (items never seen by Client 1 or 2). An ID-based model fails because the specific movie IDs don't match. However, the semantic text 'action' connects the user to Client 2's inventory, which ID models miss.
Key Novelty
GPT-FedRec (Federated Recommendation via Hybrid RAG)
- Hybrid Retrieval Mechanism: Combines a lightweight ID-based retriever (capturing user-item interaction history) with a dense text-based retriever (capturing semantic item descriptions like titles/genres) to handle data heterogeneity
- Retrieval-Augmented LLM Re-ranking: Uses the retrieved candidates to prompt a frozen LLM (GPT-3.5) for final ranking, leveraging the LLM's zero-shot generalization while constraining it to real items to prevent hallucination
Architecture
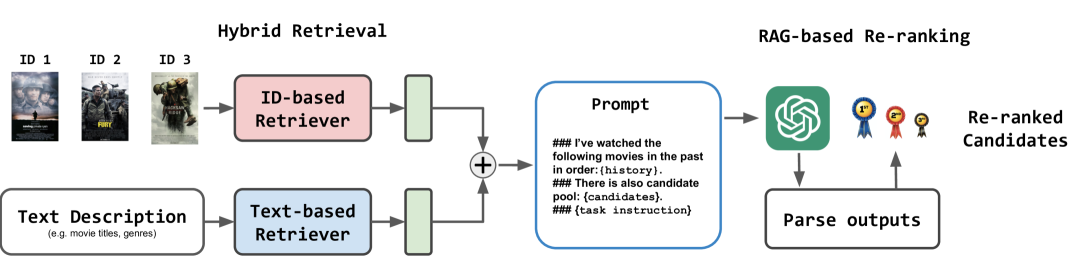
The overall two-stage framework of GPT-FedRec. Stage 1: Hybrid Retrieval using ID-based and Text-based retrievers aggregated from local clients. Stage 2: LLM-based re-ranking using GPT.
Evaluation Highlights
- Outperforms state-of-the-art baselines (including FedRec and TransFR) across three benchmark datasets (MovieLens-1M, Amazon-Beauty, Amazon-Sports)
- Effectively handles cold-start scenarios where test users interact with items never seen during the training of local clients
- Ablation studies confirm that combining ID-based and text-based retrieval yields better performance than using either alone
Breakthrough Assessment
7/10
First framework combining hybrid RAG with federated recommendation to address sparsity/heterogeneity. Good practical solution, though relies on black-box LLM (GPT-3.5) for the final stage.