📝 Paper Summary
Sequential Recommendation
LLM Preference Alignment
RecPO enhances LLM-based recommendation by replacing binary preference optimization with adaptive reward margins that explicitly model graded preference intensity and temporal recency.
Core Problem
Current LLM recommenders rely on binary preference alignment (DPO), which treats all positive interactions equally and ignores temporal dynamics, failing to capture graded user preferences (e.g., love vs. like) and the priority of immediate satisfaction.
Why it matters:
- Binary abstraction discards critical information about the strength of user aversion or affinity, leading to suboptimal ranking
- Ignoring temporal context causes models to recommend items that users might like eventually but do not want immediately (delayed gratification vs. immediate relevance)
- Standard alignment methods (like DPO) treat historical negatives as noise and filter them out, missing the opportunity to learn from what users explicitly reject
Concrete Example:
A user rates a movie 5 stars (Strongly Love) and another 3 stars (Mildly Like). A binary DPO model treats both as 'positive' target items. Furthermore, if the 5-star movie was watched years ago and the 3-star one yesterday, the model might incorrectly prioritize the older interest, ignoring the user's current context.
Key Novelty
RecPO (Recommender Preference Optimization)
- Introduces a 'preference intensity' factor into alignment, weighing training examples based on structured signals (e.g., star ratings) rather than just binary labels
- Incorporates 'temporal context' by decaying the reward margin for older interactions, forcing the model to prioritize recent relevance over historical preferences
- Utilizes a multi-negative ranking objective that preserves negative interaction history (unlike standard S-DPO), allowing the LLM to learn nuanced avoidance behaviors
Architecture
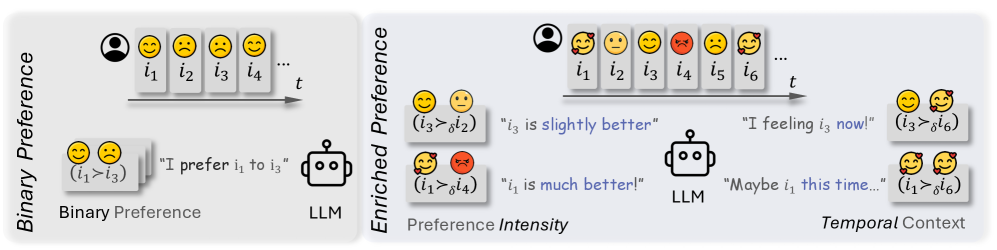
The RecPO framework pipeline, illustrating how user history and candidate items are processed with structured feedback (ratings) and temporal context to compute adaptive reward margins.
Evaluation Highlights
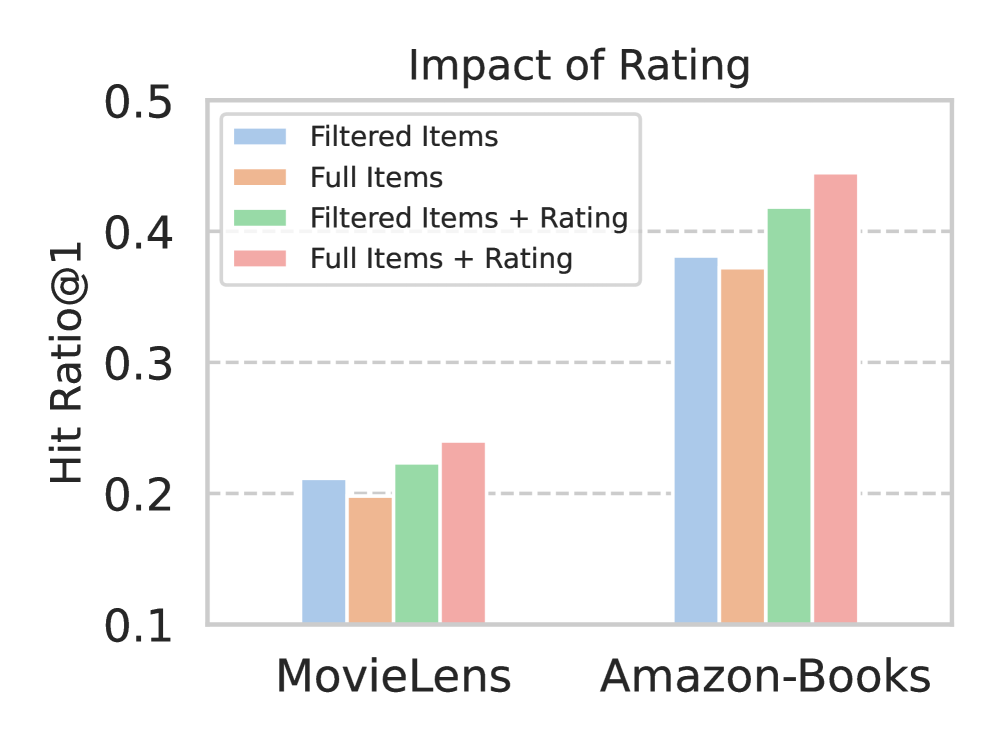
- Outperforms S-DPO by +5.49% Hit Ratio@1 on MovieLens-1M using LLaMA3-8B
- Achieves +11.1% Hit Ratio@1 improvement over S-DPO on LastFM (implicit feedback dataset) using LLaMA3-8B
- Demonstrates superior 'Avoidance Rate' (rejecting low-rated future items), surpassing S-DPO and SFT baselines across MovieLens and Steam datasets
Breakthrough Assessment
7/10
Provides a well-motivated, cognitively grounded improvement to DPO for recommendation. The gains are consistent and the analysis of temporal/intensity factors is insightful, though the core mechanism is a relatively straightforward modification of the reward margin.