📝 Paper Summary
Adversarial Machine Learning
Recommender Systems Security
LLM for Recommendation
SemanticShield detects malicious 'shilling' users in recommender systems by first filtering behavioral outliers, then using a fine-tuned LLM to audit the semantic consistency of user interaction histories.
Core Problem
Recommender systems are vulnerable to shilling attacks where fake profiles promote target items, but existing defenses rely heavily on behavioral heuristics (ratings) while ignoring the semantic inconsistency of items a fake user interacts with.
Why it matters:
- Shilling attacks undermine system reliability and user trust by artificially inflating item rankings
- Traditional defenses struggle against modern reinforcement learning-based attacks that mimic genuine rating patterns
- Behavior-only methods suffer from high false-positive rates, flagging genuine users who happen to have niche interests
Concrete Example:
A fake user profile created to boost a specific target item might interact with a random mix of 'filler' items (e.g., a horror movie, a children's cartoon, and a documentary) to hide its intent. A traditional detector sees normal rating statistics, but an LLM auditor sees semantically incoherent preferences that a real human is unlikely to have.
Key Novelty
Two-Stage Behavioral Pre-screening and Semantic Auditing
- Combines low-cost behavioral filters (PCA similarity, unpopular item ratio) to narrow down suspects with an LLM-based auditor that examines the actual titles/descriptions of items
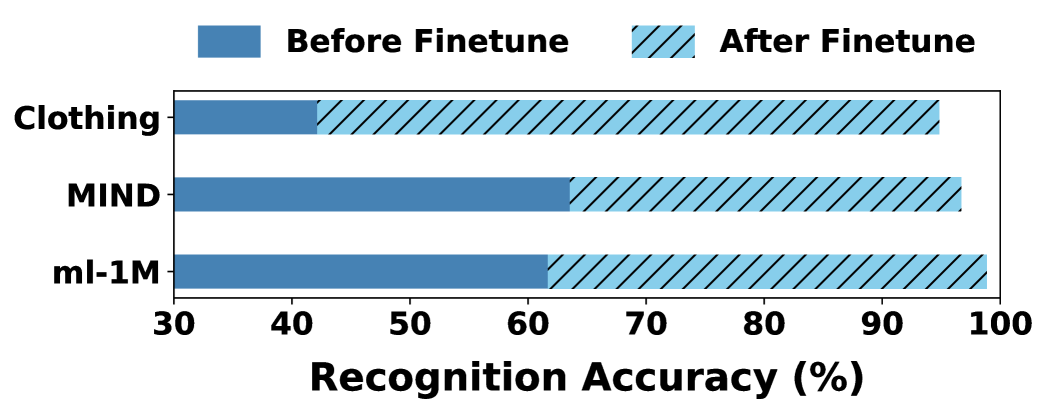
- Uses Reinforcement Fine-Tuning (RFT) with Group Relative Policy Optimization (GRPO) to specialize a smaller LLM (Qwen2.5-1.5B) for attack detection, rewarding logical consistency and correct classification
Architecture
The two-stage detection pipeline: pre-screening followed by LLM auditing.
Evaluation Highlights
- Achieves nearly 100% Detection Rate (DR) with negligible False Alarm Rate (< 0.6%) across three datasets (ML-1M, MIND, Clothing), consistently outperforming baselines like DGA-MFCA and Llama-3-70B
- Demonstrates strong generalization to unseen attack types (GOAT, FedRecAttack) with ~100% DR, whereas traditional methods often fail on novel attacks
- Maintains recommendation quality (Hit Ratio and NDCG) at nearly 100% of the clean baseline level after filtering, proving that genuine users are preserved
Breakthrough Assessment
8/10
Significantly improves detection robustness against sophisticated attacks by integrating semantic reasoning (LLMs) with traditional behavioral signals. The use of GRPO for fine-tuning a small model to outperform larger ones is a notable technical contribution.