📝 Paper Summary
Adversarial Attacks on Recommender Systems
LLM-based Agents
CheatAgent employs a Large Language Model as an autonomous attack agent to generate adversarial textual perturbations that mislead black-box LLM-empowered recommender systems into making incorrect recommendations.
Core Problem
LLM-empowered recommender systems are vulnerable to adversarial attacks, but traditional Reinforcement Learning (RL) attackers fail because they lack the language understanding and reasoning capabilities to manipulate complex textual inputs effectively.
Why it matters:
- LLM-empowered RecSys are increasingly deployed in high-stakes environments (finance, healthcare), making safety vulnerabilities critical.
- Existing black-box attackers (RL-based) cannot process textual item titles/descriptions or reason about context, leaving a gap in evaluating LLM-RecSys robustness.
- Security concerns require testing systems under practical black-box settings where model weights are inaccessible.
Concrete Example:
In a recommender system prompt asking for the top item for 'User_637' who liked 'item_1009', an attacker wishes to insert specific words or fake items into the history to force the system to recommend an irrelevant 'item_1072'. Traditional RL agents struggle to craft natural language perturbations to achieve this in a text-based prompt.
Key Novelty
CheatAgent Framework (LLM-as-Attacker)
- Replaces traditional RL attack agents with an LLM-based agent that possesses human-like reasoning and open-world knowledge to craft effective textual perturbations.
- Introduces an 'Insertion Positioning' strategy to identify optimal locations in the prompt for perturbation with minimal modification.
- Utilizes a self-reflection policy optimization (via prompt tuning) to iteratively improve the attack strategy based on feedback from the victim system.
Architecture
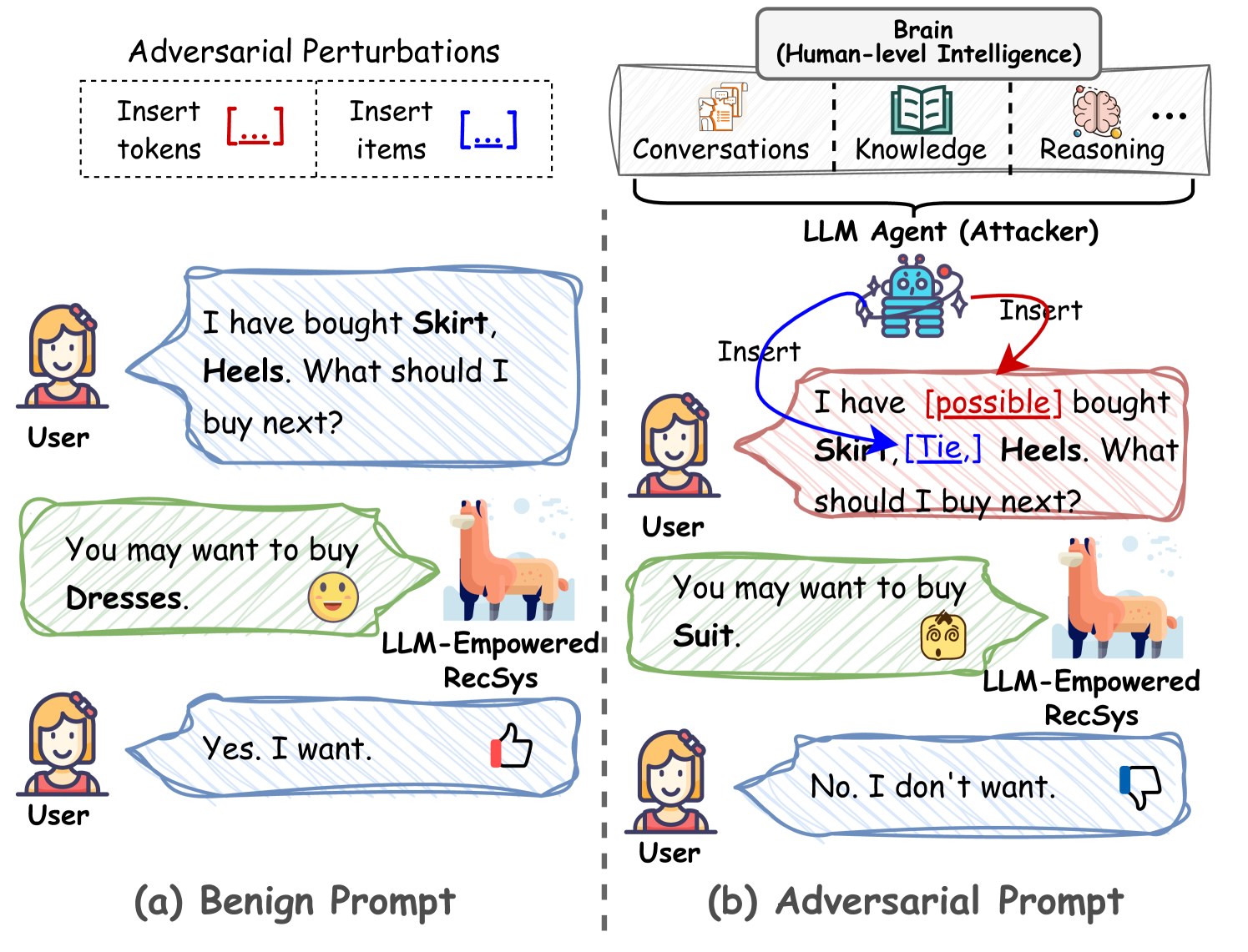
Conceptual illustration of the CheatAgent framework attacking an LLM-empowered RecSys.
Breakthrough Assessment
7/10
This is the first work to investigate the safety vulnerability of LLM-empowered RecSys specifically using an LLM-based agent. It addresses the limitations of RL-based attacks in text-heavy contexts.