📝 Paper Summary
Data Augmentation for Recommendation
LLM for ID-based Recommendation
LLM4IDRec fine-tunes Large Language Models on pure ID sequences to generate synthetic user-item interactions, augmenting training data for traditional ID-based recommenders without relying on textual metadata.
Core Problem
Most LLM-based recommendation approaches rely heavily on textual data (titles, descriptions), limiting their applicability to ID-based systems where only anonymized user-item interaction matrices are available.
Why it matters:
- Many industrial recommendation systems operate on pure ID data (anonymized interaction logs) due to privacy or data availability constraints, rendering text-dependent LLM methods unusable
- Traditional ID-based models (like GCNs) struggle with sparse interaction data; leveraging the sequential reasoning of LLMs could augment this data but has been unexplored due to the lack of semantics in IDs
Concrete Example:
In a standard LLM recommender, the input might be 'User liked The Matrix'. In an ID-based system, the input is 'User_101 liked Item_505'. Current LLMs struggle to interpret 'Item_505' without semantic context. This paper proposes fine-tuning the LLM to understand 'Item_505' as a token in a sequence to predict the next ID 'Item_606', creating a synthetic interaction to train a GCN model.
Key Novelty
LLM-driven ID Data Augmentation (LLM4IDRec)
- Treats user IDs and item IDs as vocabulary tokens for an LLM, fine-tuning the model to predict the next ID in a sequence based purely on collaborative patterns (interaction history)
- Decouples the LLM from the final recommendation inference; instead, the LLM acts as a data generator to create 'augmented' interaction logs, which are then used to train standard, efficient ID-based models (like SimGCL)
Architecture
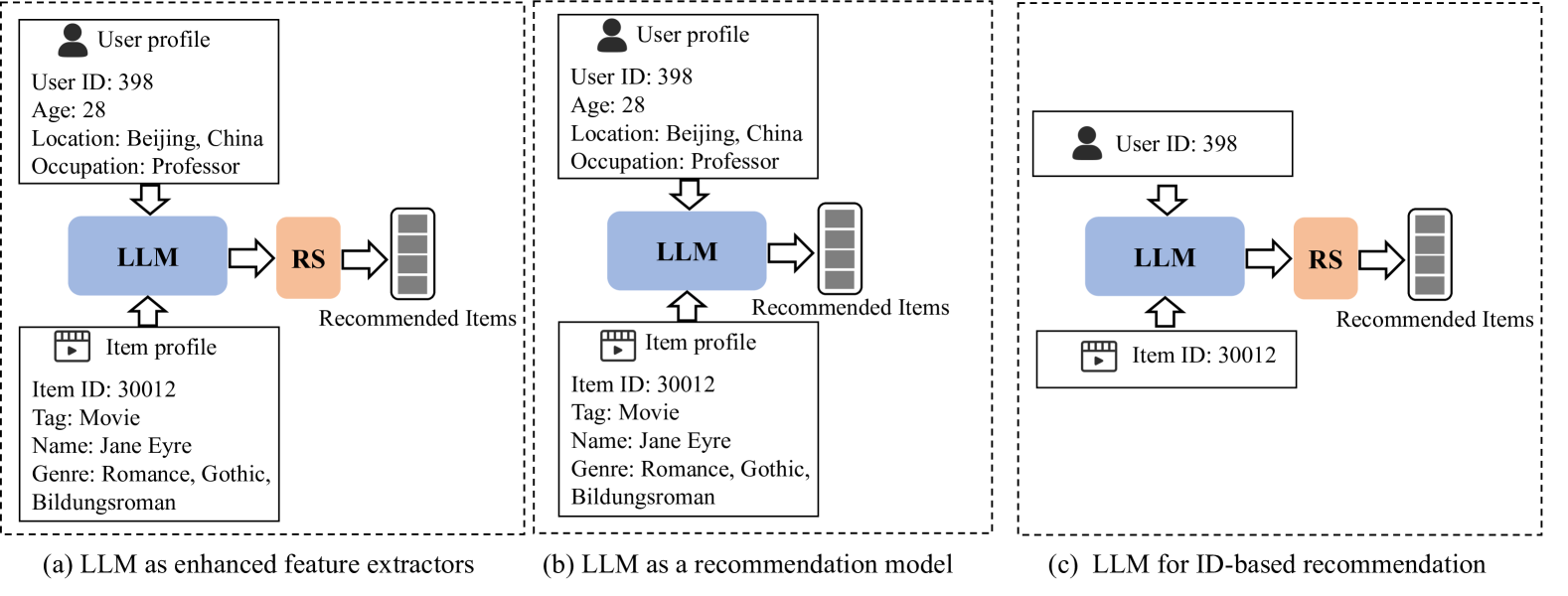
Conceptual comparison of LLM-based recommendation paradigms. 1(c) shows the proposed LLM4IDRec approach utilizing pure ID data.
Breakthrough Assessment
7/10
Novel application of LLMs to pure ID data, moving away from the text-heavy paradigm. It effectively bridges the gap between LLM reasoning and traditional collaborative filtering.