📝 Paper Summary
LLM Auditing
Recommender Systems
Fairness and Bias
LLMScholarBench benchmarks 22 LLMs to demonstrate that user interventions like RAG and constrained prompting merely redistribute errors between factual accuracy and social diversity rather than solving them.
Core Problem
Existing audits evaluate LLM scholar recommendations in isolation, ignoring how common user interventions (temperature, prompting constraints, RAG) radically alter model behavior and failure modes.
Why it matters:
- Static audits fail to predict performance in deployed systems where users actively steer models
- Biased recommendations reinforce the 'Matthew effect,' invisibilizing qualified scholars from underrepresented groups
- Users need to know if 'fixing' diversity via prompts accidentally breaks factual validity (hallucinations)
Concrete Example:
A user prompts for 'top physics experts' and adds a constraint for 'diverse candidates.' The audit reveals this intervention often causes the model to hallucinate non-existent scholars to satisfy the diversity requirement, improving representation metrics at the cost of factuality.
Key Novelty
Intervention-Based Auditing Framework
- Systematically evaluates not just base models, but the interaction between models and post-training interventions (temperature, RAG, prompting constraints)
- Separates evaluation metrics into 'Technical Quality' (validity, factuality) and 'Social Representation' (diversity, parity) to explicitly measure trade-offs between them
Architecture
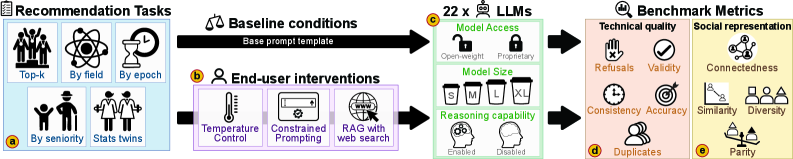
The LLMScholarBench auditing framework, illustrating the flow from infrastructure choices and user interventions to task execution and dual-axis evaluation.
Breakthrough Assessment
8/10
Significant shift from static model auditing to dynamic intervention auditing. Highlights critical trade-offs (diversity vs. factuality) often missed in standard benchmarks.