📝 Paper Summary
Automated Recommender System Design
LLM-driven Code Evolution
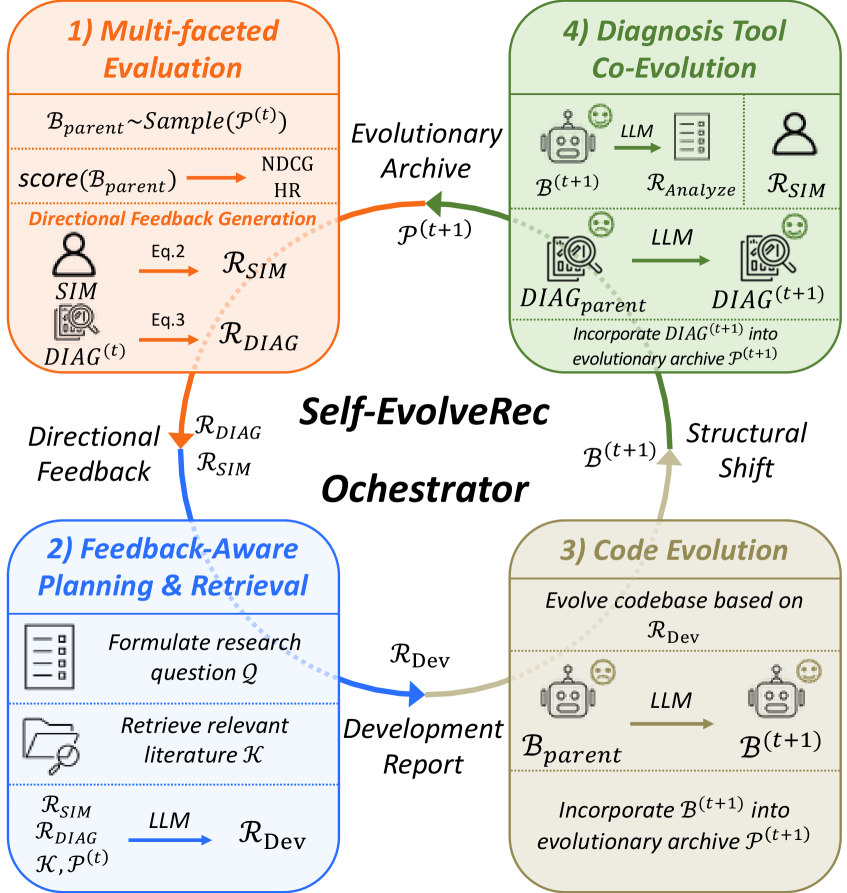
Self-EvolveRec automates recommender system design by coupling a user simulator that provides qualitative critiques with a diagnostic tool that verifies structural failures, guiding an LLM to iteratively evolve the code.
Core Problem
Existing automated design methods (NAS) are limited to fixed search spaces, while recent LLM-driven evolution relies on scalar metrics (e.g., NDCG) that fail to explain root causes of failure.
Why it matters:
- Scalar metrics cannot distinguish between different failure modes (e.g., popularity bias vs. lack of diversity), leading to undirected trial-and-error optimization.
- Manual refinement of the entire recommendation pipeline is inefficient and costly, while NAS fails to optimize non-architectural components like loss functions.
- Without diagnostic feedback, LLM agents cannot generate targeted code fixes for complex structural or behavioral deficiencies.
Concrete Example:
If a model's NDCG drops, scalar metrics don't reveal why. A user simulator might explain, 'I seek low-cost accessories, not expensive electronics,' pinpointing a semantic mismatch that a single number hides.
Key Novelty
Directional Feedback Loop with Co-Evolution
- Integrates a User Simulator for qualitative natural language critiques (e.g., 'too much repetition') with a Model Diagnosis Tool for quantitative verification (e.g., measuring embedding collapse).
- Implements a 'Co-Evolution' strategy where the diagnosis tool itself evolves alongside the recommender, generating new metrics to mathematically verify the simulator's subjective complaints.
Architecture
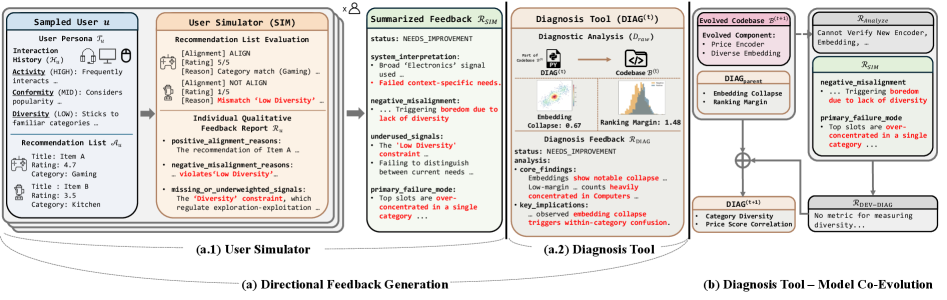
Overview of Self-EvolveRec framework, highlighting the Directional Feedback Generation (User Simulator + Model Diagnosis) and the Co-Evolution process.
Evaluation Highlights
- Outperforms state-of-the-art NAS and LLM-driven baselines in recommendation performance and user satisfaction.
- Validates that directional feedback leads to deterministic improvements in technical quality of evolved algorithmic logic.
- Demonstrates the ability to resolve structural failures like embedding collapse through targeted diagnostic interventions.
Breakthrough Assessment
8/10
Significant step forward in agentic coding for RecSys. Moving from scalar-metric optimization to qualitative/diagnostic feedback loops is a strong methodological contribution.