📝 Paper Summary
LLM Evaluation Metrics
Mechanistic Interpretability
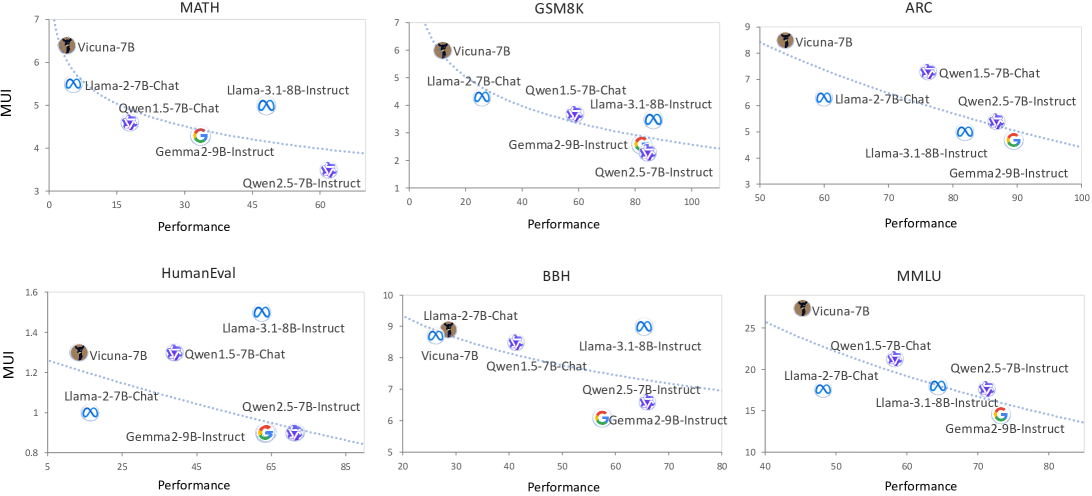
MUI evaluates Large Language Models by measuring the proportion of neurons or features activated during inference, postulating that stronger models achieve better performance with lower activation effort.
Core Problem
Standard LLM benchmarks are bounded and cannot fully capture the near-unbounded generalization capabilities of scaling models, making it difficult to estimate true potential beyond limited test samples.
Why it matters:
- Relying solely on performance scores fails to distinguish between rote memorization (high effort) and true capability (low effort)
- Benchmarks saturate or become contaminated, inflating scores without reflecting actual model improvements
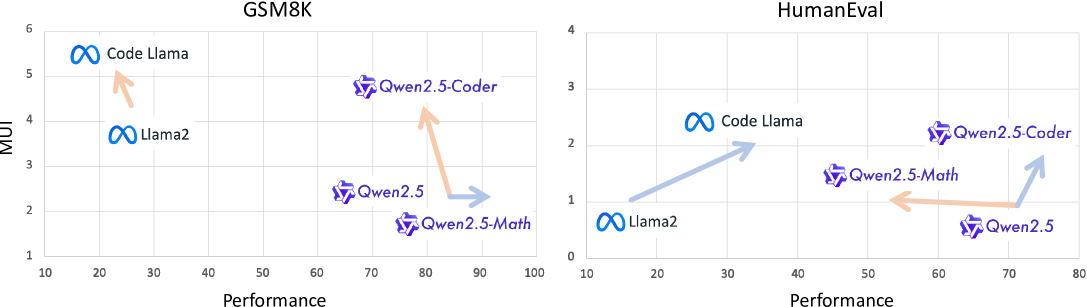
- Researchers lack metrics to diagnose training dynamics like 'coarsening' (improving one task while degrading others)
Concrete Example:
Two models might achieve similar scores on a leaderboard, but one relies on 'brute force' utilization of its network (high MUI), while the other achieves the same result with sparse activation (low MUI), indicating superior fundamental capability and efficiency.
Key Novelty
Model Utilization Index (MUI)
- Defines 'effort' as the ratio of activated neurons or sparse autoencoder features utilized to solve a specific task relative to the model's total capacity
- Establishes the 'Utility Law': an inverse logarithmic relationship exists between model performance and utilization effort (better models use less of their capacity)
- Uses mechanistic interpretability (neuron patching/SAE) to quantify exactly which components are causal for a specific output
Architecture
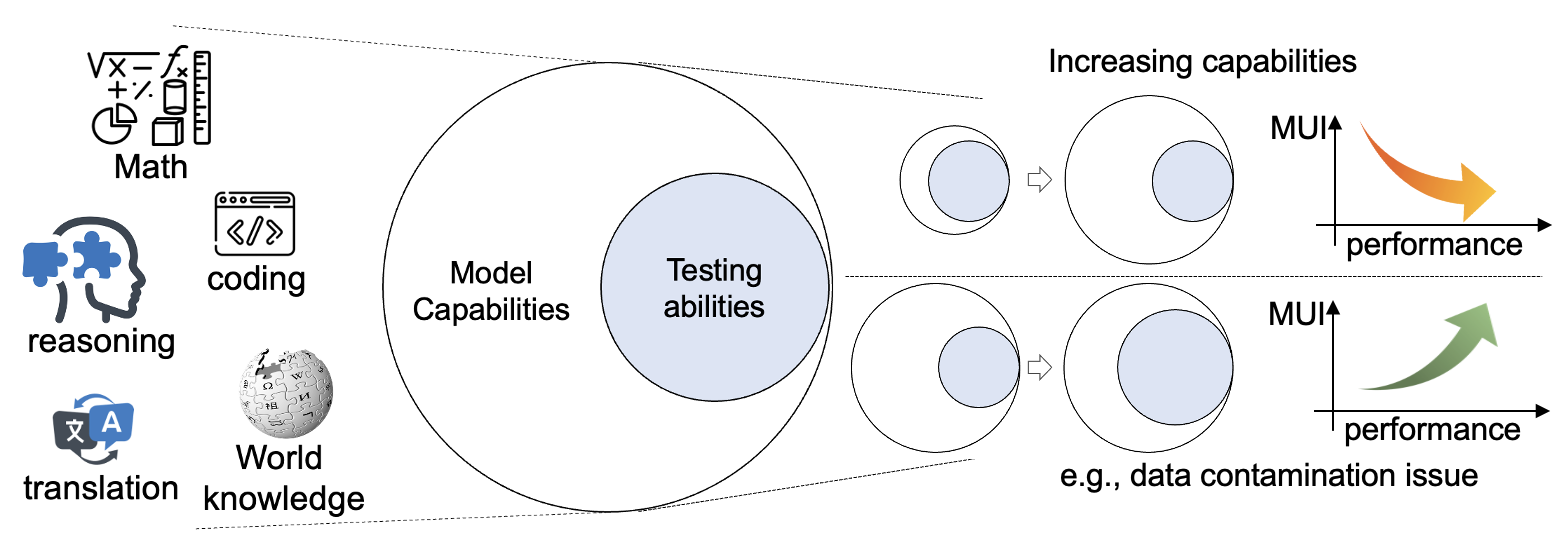
Conceptual illustration of Model Utilization Index (MUI) showing a model's total capability versus the subset activated for a specific task.
Evaluation Highlights
- Demonstrates a consistent negative logarithmic relationship (A=-3.534, B=26.049) between MUI and performance across Llama, Qwen, and Gemma model families
- Identifies a theoretical 'limit sparsity ratio' of ~9.77% utilization when performance reaches 100%, guiding optimal model compression
- Successfully detects data contamination by observing 'Collapsing' behavior (lower MUI with falsely high performance) distinct from genuine learning curves
Breakthrough Assessment
8/10
Proposes a novel, interpretability-grounded dimension for evaluation that complements standard accuracy. Theoretical framing (Utility Law) and practical applications (contamination detection) are significant contributions.