📝 Paper Summary
Generative Recommendation
LLM Alignment
Reinforcement Learning
Align3GR is a generative recommendation framework that unifies semantic-collaborative tokenization, behavior-aligned fine-tuning, and progressive preference optimization to bridge the gap between LLMs and recommender systems.
Core Problem
LLMs excel at semantic reasoning but struggle with recommendation because they lack alignment with collaborative signals (user-item interactions) and real-world user preferences.
Why it matters:
- Standard language modeling (next-token prediction) does not inherently capture the implicit preference signals required for personalized recommendation
- Existing methods often tokenize users and items independently, ignoring the mutual collaborative dependencies critical for accurate preference modeling
- Static preference optimization fails to adapt to the complex, dynamic, and sparse feedback found in real-world industrial recommendation scenarios
Concrete Example:
Current approaches may tokenize items based on content but treat users merely as text profiles. This causes the model to recommend items that are semantically similar to a user's description but fail to reflect their actual behavioral history (collaborative signal), such as buying items that don't match their stated profile.
Key Novelty
Unified Multi-Level Alignment (Token, Behavior, Preference)
- Introduces Dual SCID Tokenization that jointly encodes user and item features (semantic + collaborative) into a shared discrete token space using a dual-track fusion strategy
- Implements a Progressive DPO strategy that moves from 'easy' self-play samples to 'hard' real-world feedback, allowing the model to learn preferences via a curriculum
Architecture
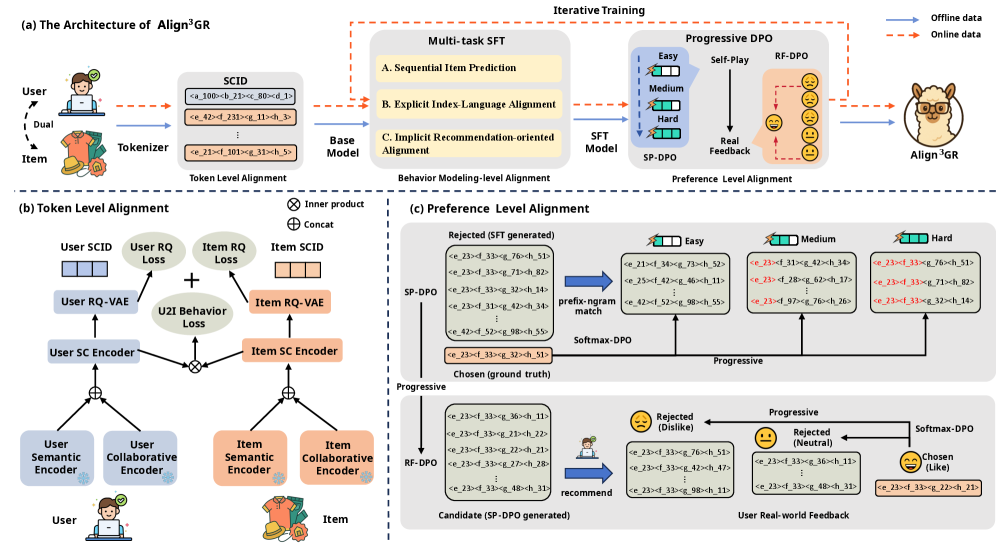
The overall framework of Align3GR, illustrating the three alignment levels: Token-level (Dual SCID), Behavior-level (Multi-task SFT), and Preference-level (Progressive DPO).
Evaluation Highlights
- +17.8% improvement in Recall@10 on the public Instruments dataset compared to the SOTA baseline
- +20.2% improvement in NDCG@10 on the public Instruments dataset compared to the SOTA baseline
Breakthrough Assessment
8/10
Proposes a comprehensive full-stack solution (tokenization to RL) with significant double-digit gains over SOTA and verified industrial deployment, though code is not provided.