📝 Paper Summary
Continual Learning
Generative Recommendation
Parameter-Efficient Fine-Tuning (PEFT)
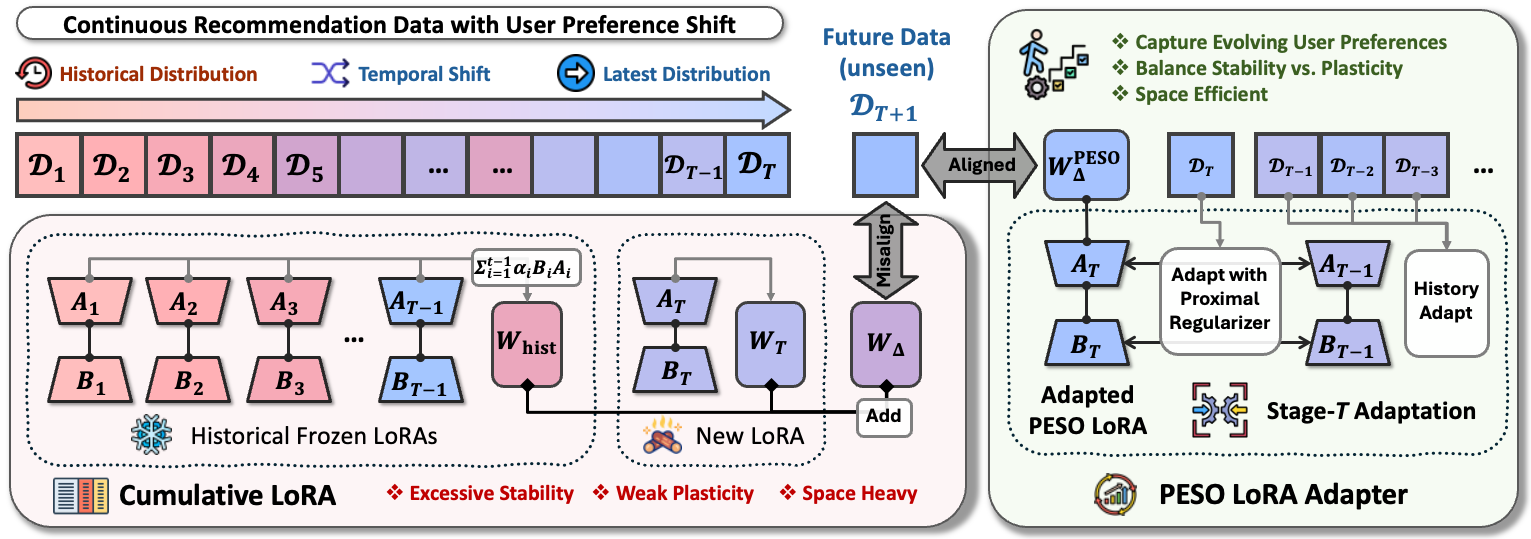
PESO enables large language models to adapt to evolving user preferences in recommendation by maintaining a single LoRA adapter that is mathematically anchored to its previous state, preventing catastrophic forgetting without freezing outdated knowledge.
Core Problem
Standard continual learning methods (like cumulative LoRA) assume tasks are disjoint and aim to preserve all past knowledge, but in recommendation, user preferences evolve and old preferences (e.g., outgrown hobbies) can actively degrade performance if forcefully preserved.
Why it matters:
- Real-world recommendation data arrives sequentially, making retraining from scratch inefficient
- Existing cumulative methods from computer vision fail in recommendation because they entangle outdated preferences with relevant ones
- Outdated preferences must sometimes be overwritten (plasticity) rather than preserved (stability) to capture current user interests accurately
Concrete Example:
A user who previously watched action movies but shifted to romance will be recommended irrelevant action titles if the model rigidly preserves the old 'action' adapter. PESO allows the old preference to fade if recent data doesn't support it, while retaining stable long-term interests.
Key Novelty
Proximally Regularized Single Evolving LoRA (PESO)
- Rejects the 'cumulative adapter' approach (stacking frozen modules) in favor of a single evolving adapter to avoid entangling outdated knowledge
- Introduces a Softmax-KL proximal regularization term that acts as a 'soft anchor,' pulling the adapter towards its previous state only when new data doesn't strongly suggest a change
- Theoretically proves that this regularization provides data-aware, direction-wise guidance, updating parameters along directions supported by new data while freezing unsupported directions
Architecture
Conceptual comparison of PESO vs. Cumulative LoRA strategies. Shows PESO maintaining a single adapter v_t anchored to v_{t-1}, while Cumulative LoRA stacks frozen history.
Evaluation Highlights
- Demonstrates that Cumulative LoRA (summing past adapters) performs worse than a single evolving adapter on natural chronological splits, contradicting findings in computer vision
- The proposed Softmax-KL proximal regularizer functions as an 'app-weighted variance' penalty, preserving internal module structure better than standard L2 regularization
- Analysis confirms that parameter inheritance (initializing from the previous stage) is critical for performance, while aggregating old frozen adapters hinders adaptation to evolving preferences
Breakthrough Assessment
7/10
Provides a strong theoretical correction to the blind application of Computer Vision continual learning techniques (Cumulative LoRA) to Recommendation, identifying why they fail and proposing a mathematically grounded alternative.