📝 Paper Summary
AI in Education
Personalized Learning Path Recommendation
Multi-Objective Reinforcement Learning
IB-GRPO aligns LLMs for personalized education by warm-starting with synthetic hybrid experts and optimizing multiple conflicting objectives (learning effect, diversity, difficulty) using a dominance-indicator-based reinforcement learning approach.
Core Problem
Applying LLMs to long-horizon learning path recommendation fails due to misalignment with pedagogical goals (like ZPD), scarcity of expert demonstrations, and the difficulty of balancing conflicting objectives (e.g., learning effect vs. diversity) using traditional scalar rewards.
Why it matters:
- LLMs pre-trained on generic text often prioritize plausibility over long-term educational outcomes, failing to adapt difficulty to student proficiency.
- Existing methods rely on manual weight tuning to combine rewards, which obscures trade-offs and fails to capture the true Pareto frontier of educational goals.
- Collecting high-quality expert demonstrations for learning paths is expensive and scarce, making the 'cold start' for RL fine-tuning inefficient.
Concrete Example:
A standard LLM might recommend a learning path that looks coherent but is too easy for a student (violating ZPD), or it might repetitively recommend similar exercises to maximize a narrow reward signal, failing to provide the diversity needed for robust learning.
Key Novelty
Indicator-Based Group Relative Policy Optimization (IB-GRPO)
- Replaces manual reward weighting with an evolutionary-inspired dominance indicator ($I_{\epsilon+}$) that calculates how much a generated path dominates others in the sampled group across multiple objectives.
- Constructs a 'Hybrid Expert' dataset for supervised warm-start by combining Genetic Algorithm (global search) with traditional RL agents (local exploitation) to create diverse, high-quality synthetic demonstrations.
Architecture
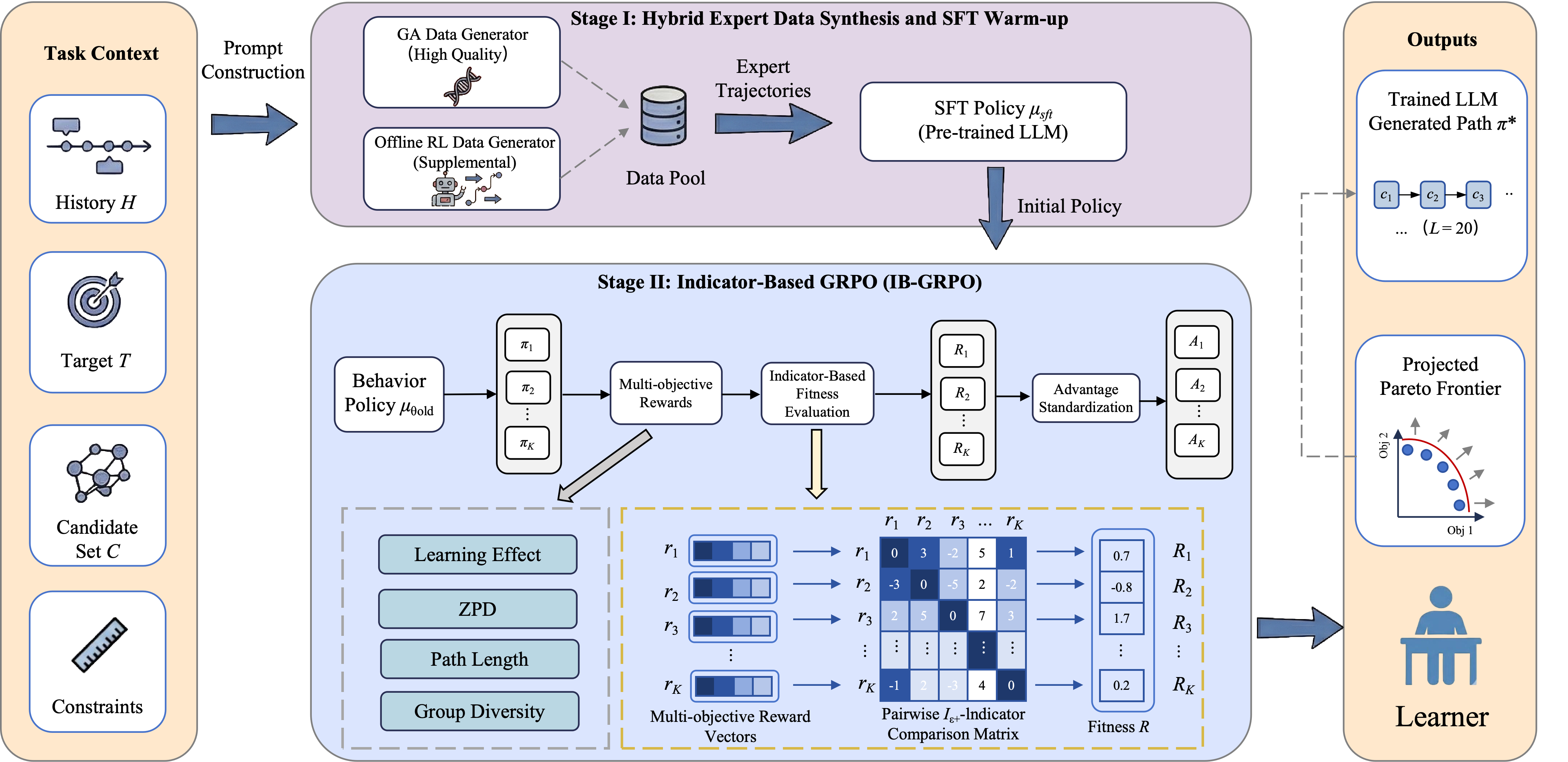
The two-stage framework: (1) Hybrid Expert Data Synthesis & SFT, and (2) IB-GRPO Alignment.
Breakthrough Assessment
7/10
Novel integration of evolutionary dominance indicators into the GRPO framework to solve multi-objective alignment without scalarization, applied effectively to a complex educational domain.