📝 Paper Summary
LLM for Recommendation (LLM4Rec)
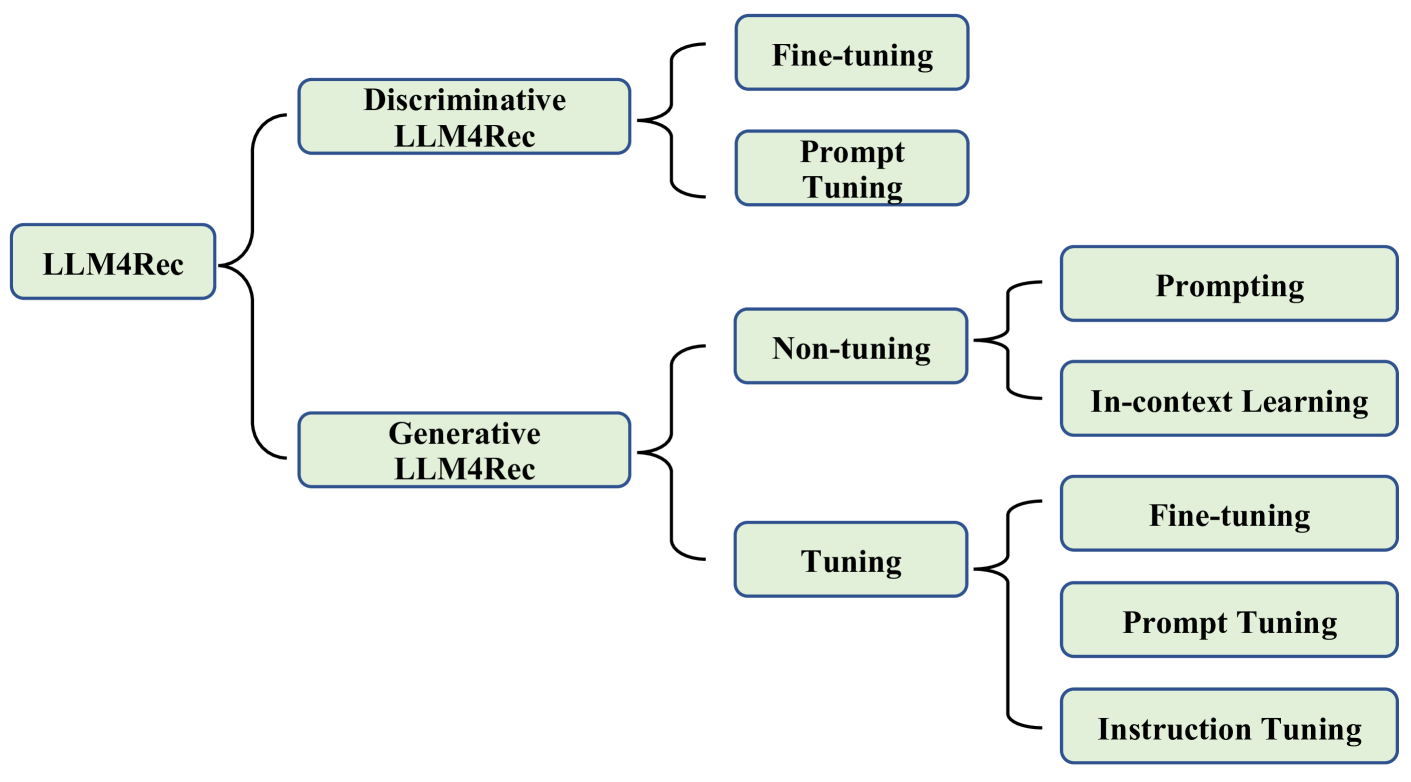
Discriminative vs. Generative Recommendation
This survey establishes a comprehensive taxonomy for LLM-based recommendation systems, categorizing them into Discriminative and Generative paradigms to systematically analyze how they address data sparsity and personalization.
Core Problem
Traditional recommendation systems struggle with data sparsity (limited interactions) and lack deep textual understanding; prior surveys focused on pre-training transfer techniques rather than the emerging capabilities of Generative LLMs.
Why it matters:
- Conventional ID-based recommenders fail in cold-start scenarios where historical interaction data is scarce
- Generative LLMs (like ChatGPT) offer unused potential for explainability and conversational recommendation that traditional discriminative models cannot provide
- Existing literature lacks a systematic categorization of how to adapt generative paradigms (tuning vs. non-tuning) for recommendation tasks
Concrete Example:
In a 'near cold-start' scenario, a traditional Collaborative Filtering model fails due to lack of user history, whereas an LLM-based system using 'Language only' prompts (describing user preferences) can generate valid recommendations zero-shot.
Key Novelty
Taxonomy of Discriminative vs. Generative LLMs for Recommendation
- Categorizes existing works into Discriminative LLMs (DLLM4Rec, mainly BERT-based embeddings) and Generative LLMs (GLLM4Rec, mainly GPT-based generation)
- Defines three distinct modeling paradigms: (1) LLM as Embedding Extractor, (2) LLM as Token Generator (semantic mining), and (3) LLM as Standalone Recommender (end-to-end)
Architecture
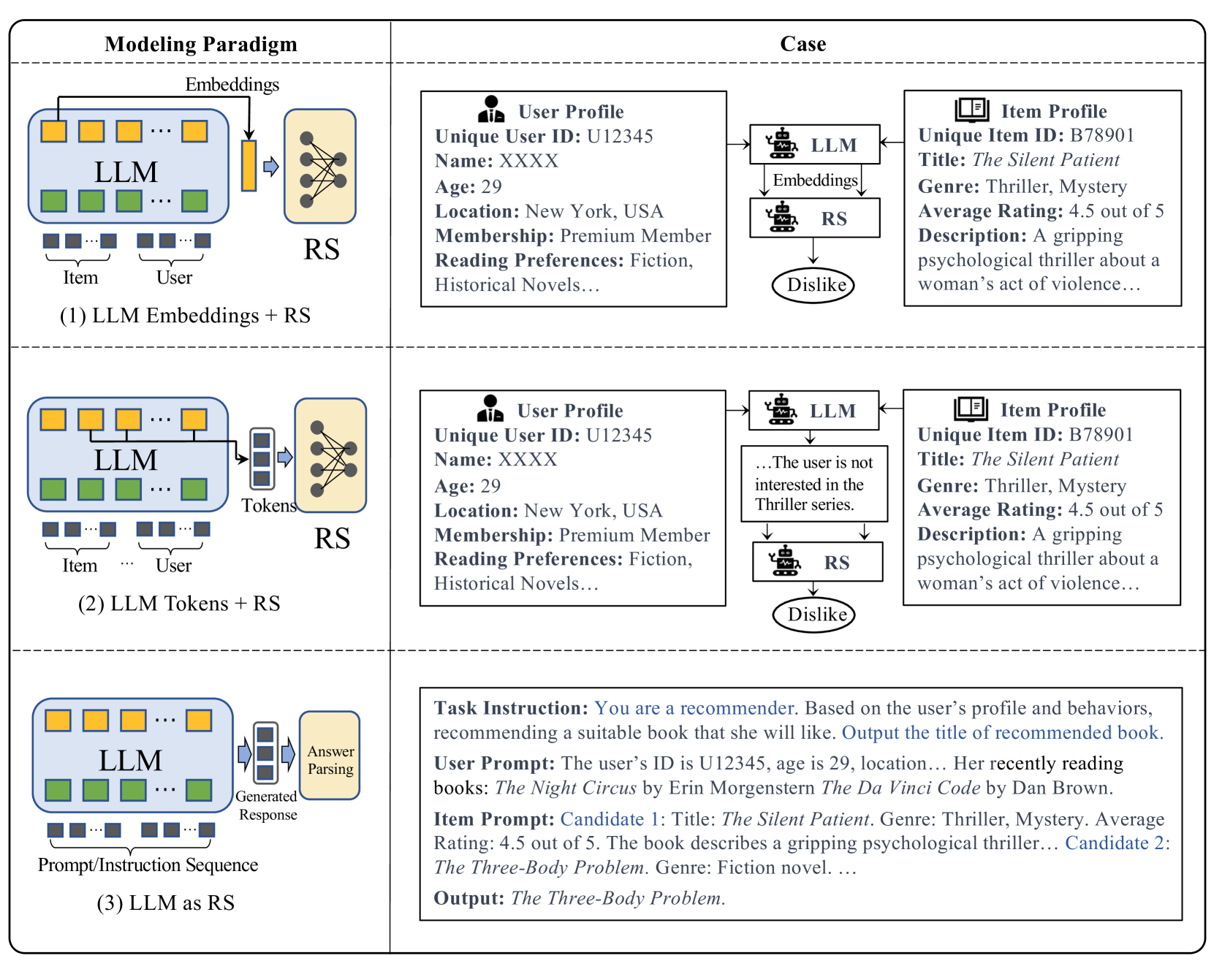
The three modeling paradigms for adapting LLMs to Recommendation Systems
Breakthrough Assessment
8/10
A foundational survey that organizes a rapidly exploding field. While it doesn't propose a new model, its taxonomy (DLLM vs GLLM) and paradigm definitions provide the necessary structure for future research.