📝 Paper Summary
LLM-based Recommendation (LLM4Rec)
Efficient Inference
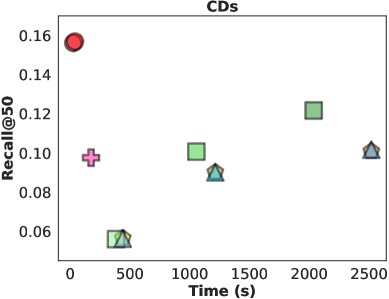
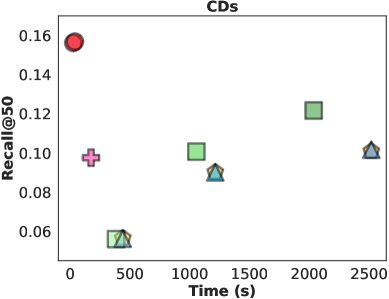
L2D accelerates LLM-based recommendation by replacing slow text generation with fast vector matching in the model's internal latent space, preserving performance while reducing latency.
Core Problem
Fine-tuned LLMs for recommendation suffer from high latency due to autoregressive decoding, where generating a list of item titles requires sequentially predicting tokens one by one.
Why it matters:
- Each recommendation request typically requires generating a list of items, causing costs to scale linearly with list size
- Autoregressive generation waits for all preceding tokens, making real-time deployment of LLM recommenders computationally prohibitive
- Existing grounding techniques that map one generated item to multiple real items can cause up to a 50% performance drop
Concrete Example:
Generating a list of 10 items for a user requires the LLM to sequentially output hundreds of tokens (titles). L2D avoids this by outputting a single vector representation that is instantly matched against candidate items.
Key Novelty
Light Latent-space Decoding (L2D)
- Treats the LLM's final hidden state as a 'thought' representation of the user's preferred item, bypassing the need to translate this thought into text tokens
- Pre-computes vector representations for all candidate items by aggregating the hidden states of training examples where those items were the ground truth
- Decodes recommendations by simply finding the nearest pre-computed item vectors to the test user's current hidden state vector
Architecture
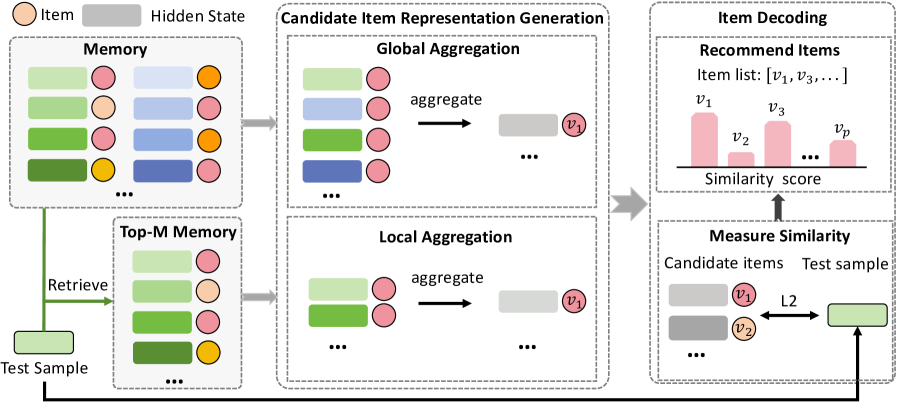
The L2D framework process: Memory Construction, Representation Generation, and Item Decoding.
Evaluation Highlights
- Reduces inference latency by >10x compared to standard language-space decoding (beam search) while maintaining comparable accuracy
- Outperforms efficient LLM-based embedding baseline AlphaRec by reducing costs by at least 5x while achieving better Recall and NDCG
- Achieves higher Recall@20 than standard decoding (beam=1) on Amazon Games (+11.2% relative improvement for ID-based classifier variant)
Breakthrough Assessment
7/10
Significant efficiency gain (>10x) for LLM recommenders with a simple, effective method. Successfully bridges generative training with discriminative inference.