📝 Paper Summary
Multilingual Language Models
Open Source Foundation Models
Lucie-7B is an open foundation model trained on a massive multilingual dataset with equal French and English representation, prioritizing data rights and transparency.
Core Problem
Mainstream LLMs like Llama are heavily English-centric, leading to poor cultural and linguistic performance for other languages, while often training on copyrighted data without transparency.
Why it matters:
- English-centric bias results in models that lack knowledge of specific cultural history, social practices, and everyday activities of non-English communities (e.g., French cooking or history).
- Dependence on opaque datasets raises legal and ethical issues regarding copyright, intellectual property, and personally identifying information.
Concrete Example:
When asked about history or cooking, an English-centric model is likely to provide answers suited to Anglophone culture rather than French culture, leading to unsatisfying results for French speakers.
Key Novelty
OpenLLM-France Lucie Project
- Constructs a training dataset with a 33% French / 33% English split to explicitly offset Anglo-centric bias.
- Prioritizes data rights by minimizing copyrighted material and maximizing public domain sources (e.g., Gallica, arguably the largest pre-processed French text collection).
- Achieves OSI (Open Source Initiative) compliance by releasing weights, code, and the full training dataset breakdown.
Architecture
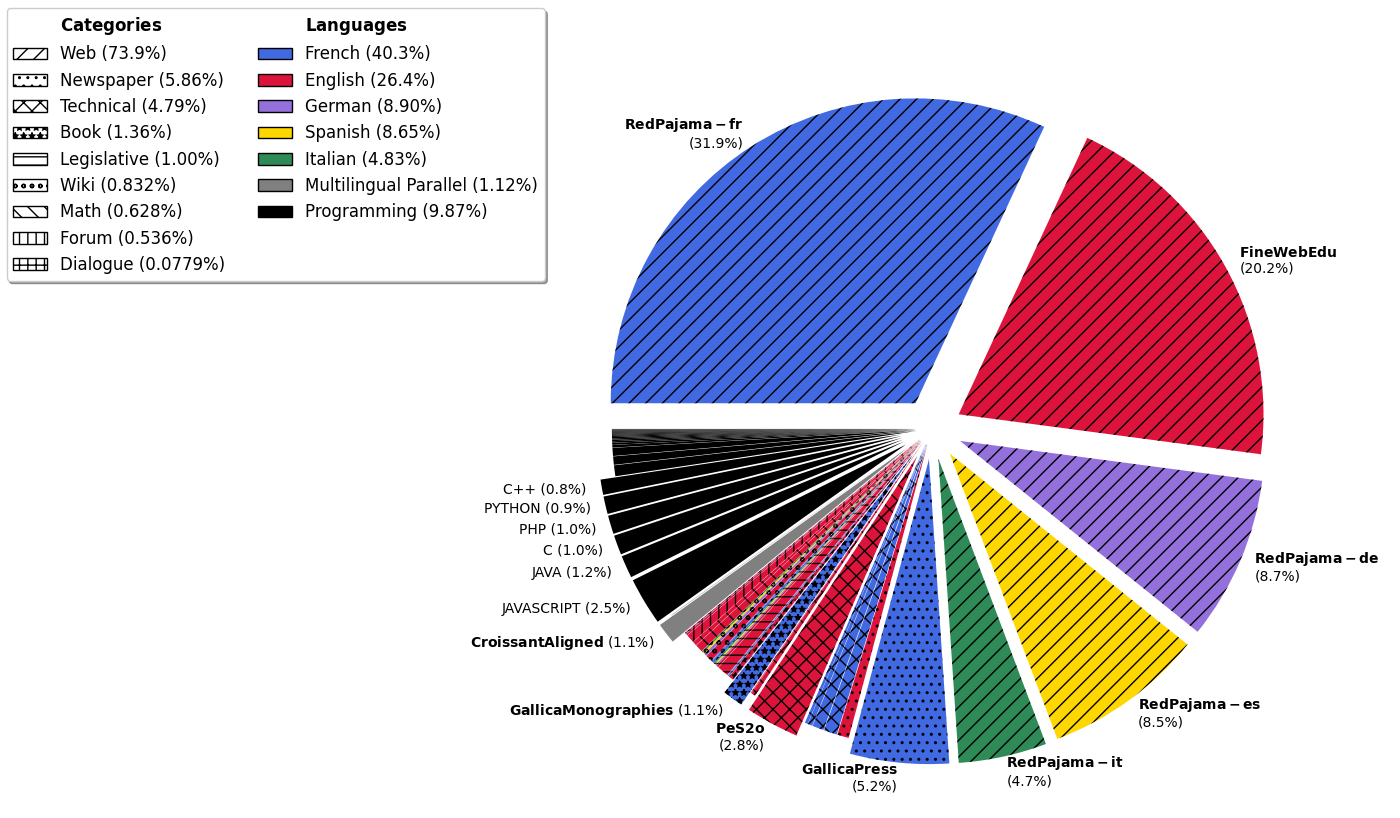
Charts showing the distribution of the Lucie Training Dataset by source category and language.
Evaluation Highlights
- Lucie-7B-Instruct-v1.1 achieves promising results compared to state-of-the-art models (specific numbers not detailed in the provided text excerpt).
- The Lucie Training Dataset is one of the biggest collections of French text data preprocessed for LLM training (40% of the raw data is French).
- Foundation model trained on roughly 33% English and 33% French data to balance cultural representation.
Breakthrough Assessment
7/10
Significant contribution to open science and non-English (French) NLP through transparent data curation and OSI compliance, though the model architecture itself is standard.