📝 Paper Summary
Generative Recommendation
LLM-based Recommendation
GenRec reframes recommendation as a conditional text generation task, fine-tuning a Large Language Model with LoRA to directly generate the next item's title from user history.
Core Problem
Traditional recommendation systems rely on discriminative ranking of item IDs, which struggles with sparsity and ignores rich semantic information in item names.
Why it matters:
- Collaborative filtering fails on cold-start items lacking interaction history IDs
- Ranking-based methods become computationally expensive as the candidate item pool grows
- ID-based models discard the semantic knowledge LLMs have about item content (e.g., titles)
Concrete Example:
In a movie recommendation scenario, a standard model sees a user watched items [ID_101, ID_405] and tries to rank [ID_888] against thousands of others. GenRec reads 'Pinocchio (1940), Legends of the Fall (1994)' and directly generates 'In the Line of Fire (1993)' by leveraging semantic understanding of the viewing habits.
Key Novelty
Generative Recommendation via Text Generation
- Paradigm Shift: Instead of calculating a score for every candidate item (discriminative), the model generates the target item's name directly (generative)
- Semantic Utilization: Uses the actual text of item titles as input/output rather than abstract numerical IDs, allowing the LLM to apply its pre-trained world knowledge
Architecture
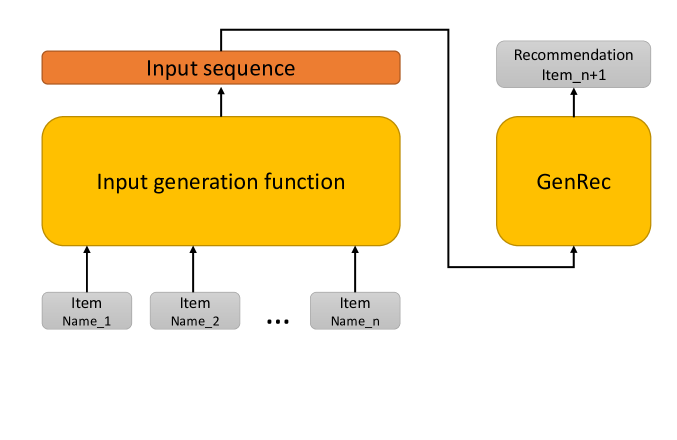
The GenRec framework pipeline: Interaction Sequence → Prompt Formatting → LLaMA-LoRA Fine-tuning → Next Item Prediction
Evaluation Highlights
- +3.46 percentage points HR@5 improvement over P5 baseline on MovieLens 25M (0.1034 vs 0.0688)
- +2.52 percentage points NDCG@5 improvement over P5 baseline on MovieLens 25M (0.0716 vs 0.0464)
- Demonstrates trade-offs: GenRec underperforms P5 on Amazon Toys, suggesting it relies heavily on rich semantic data (movie titles) absent in sparser datasets
Breakthrough Assessment
7/10
Significant step in the 'Generative Recommendation' paradigm, moving away from ranking. Strong results on text-rich datasets, though the performance drop on Amazon Toys indicates limitations in universality.