📝 Paper Summary
Modularized RAG pipeline
Next Point-of-Interest (POI) Recommendation
Zero-shot LLM reasoning
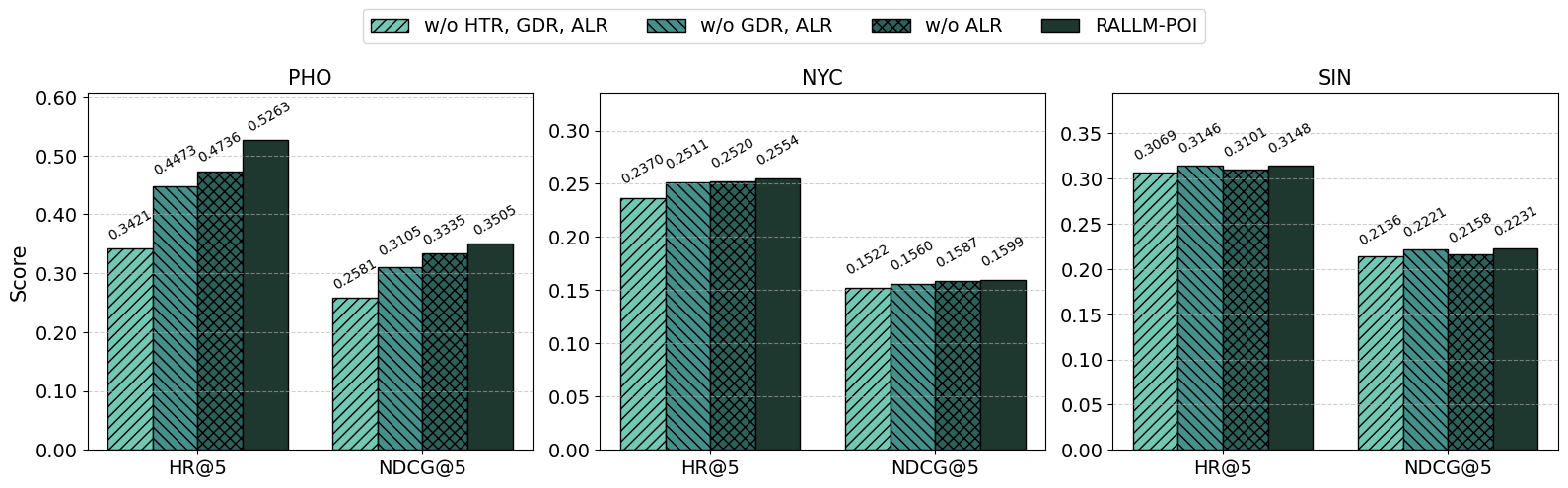
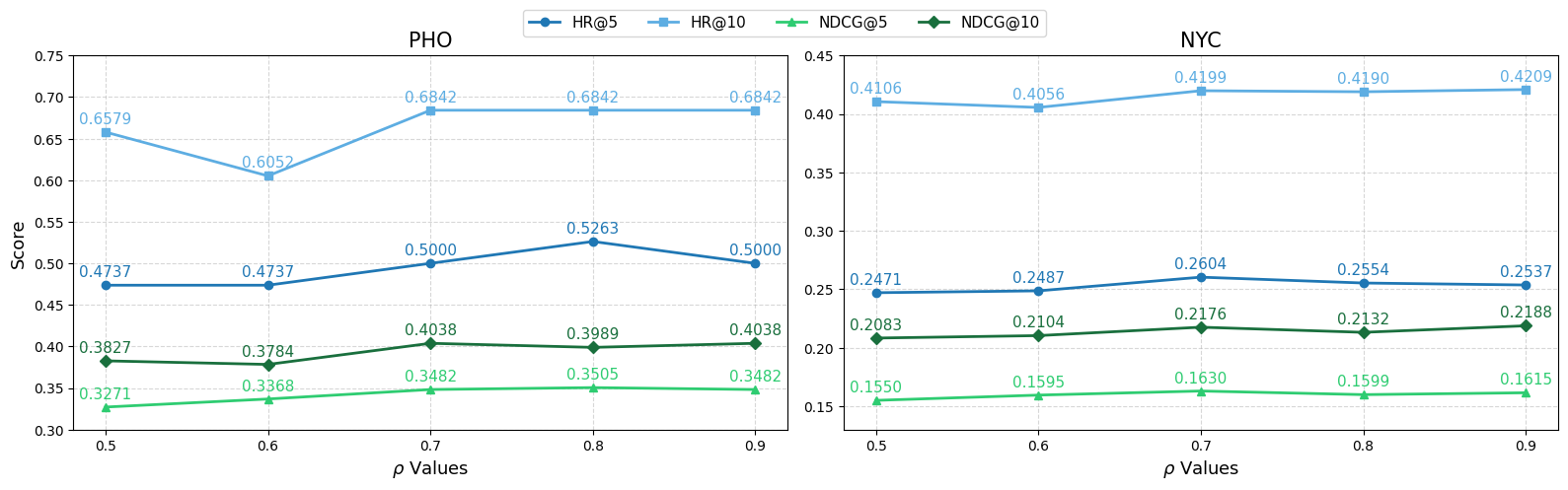
RALLM-POI improves zero-shot POI recommendation by retrieving similar historical trajectories, reranking them based on geographical distance to the user's current path, and using an agentic LLM to self-correct the final prediction.
Core Problem
Standard zero-shot LLM approaches for POI recommendation often fail because generic prompts lack relevant context, while simple retrieval methods may fetch spatially incoherent trajectories that distract the model.
Why it matters:
- Accurate POI prediction improves urban planning, traffic management, and LBSN user experience.
- Traditional deep learning models suffer from cold-start and data sparsity issues, limiting real-world effectiveness.
- Existing zero-shot LLM methods often hallucinate or provide geographically impossible recommendations due to a lack of grounded spatial context.
Concrete Example:
A user traveling in downtown Singapore might get a recommendation for a POI in a distant suburb if the LLM relies on generic popularity or irrelevant past history, whereas RALLM-POI retrieves trajectories with similar spatial patterns to constrain the prediction to the downtown area.
Key Novelty
Geographically-Aware RAG with Agentic Self-Correction
- Retrieves historical trajectories based on semantic similarity (TF-IDF) to provide grounded examples.
- Reranks these retrieved examples using a novel Decaying Weighted Dynamic Time Warping (DWDTW) metric that prioritizes spatial alignment with the user's recent movement.
- employs an 'Agentic' self-reflection step where the LLM critiques and fixes its own output to ensure validity and format compliance.
Architecture
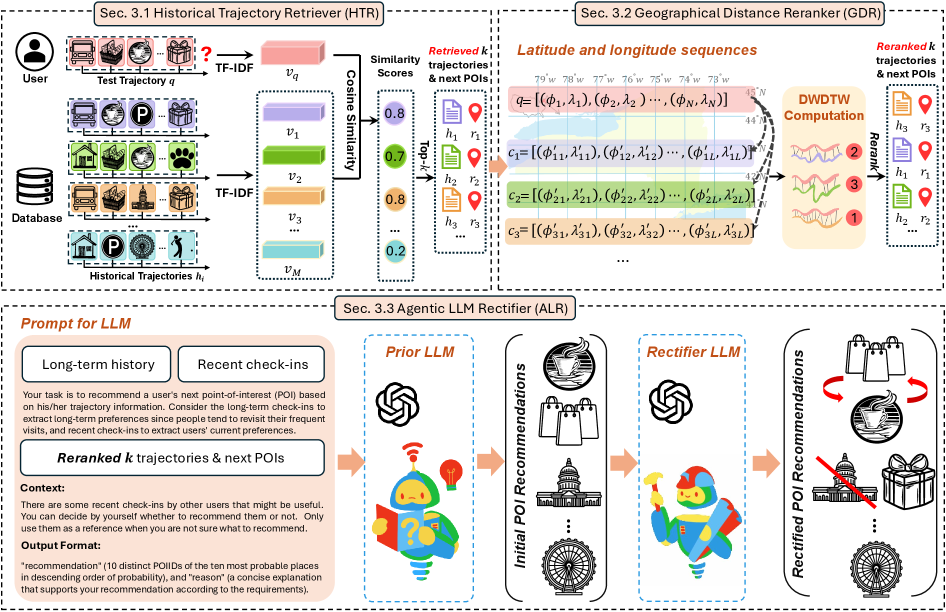
The overall inference pipeline of RALLM-POI.
Evaluation Highlights
- Outperforms state-of-the-art transformer baselines (CFPRec, CTLE) on Phoenix (PHO) and Singapore (SIN) datasets in zero-shot settings.
- Achieves ~5-10% improvement in Hit Ratio (HR@5) on the PHO dataset compared to the best baseline.
- Effective for cold-start users (inactive), often outperforming very active users due to the retrieval of rich proxy histories from the database.
Breakthrough Assessment
7/10
Solid application of RAG and agentic flows to the specific domain of POI recommendation. The geographical reranking is a domain-specific innovation that addresses a key weakness of generic RAG.