📝 Paper Summary
Collaborative Filtering
Linear Autoencoders
LLM-Enhanced Recommendation
L3AE integrates LLM-derived semantic item embeddings into linear autoencoders via a two-phase closed-form optimization that distills semantic correlations into the collaborative filtering weight matrix.
Core Problem
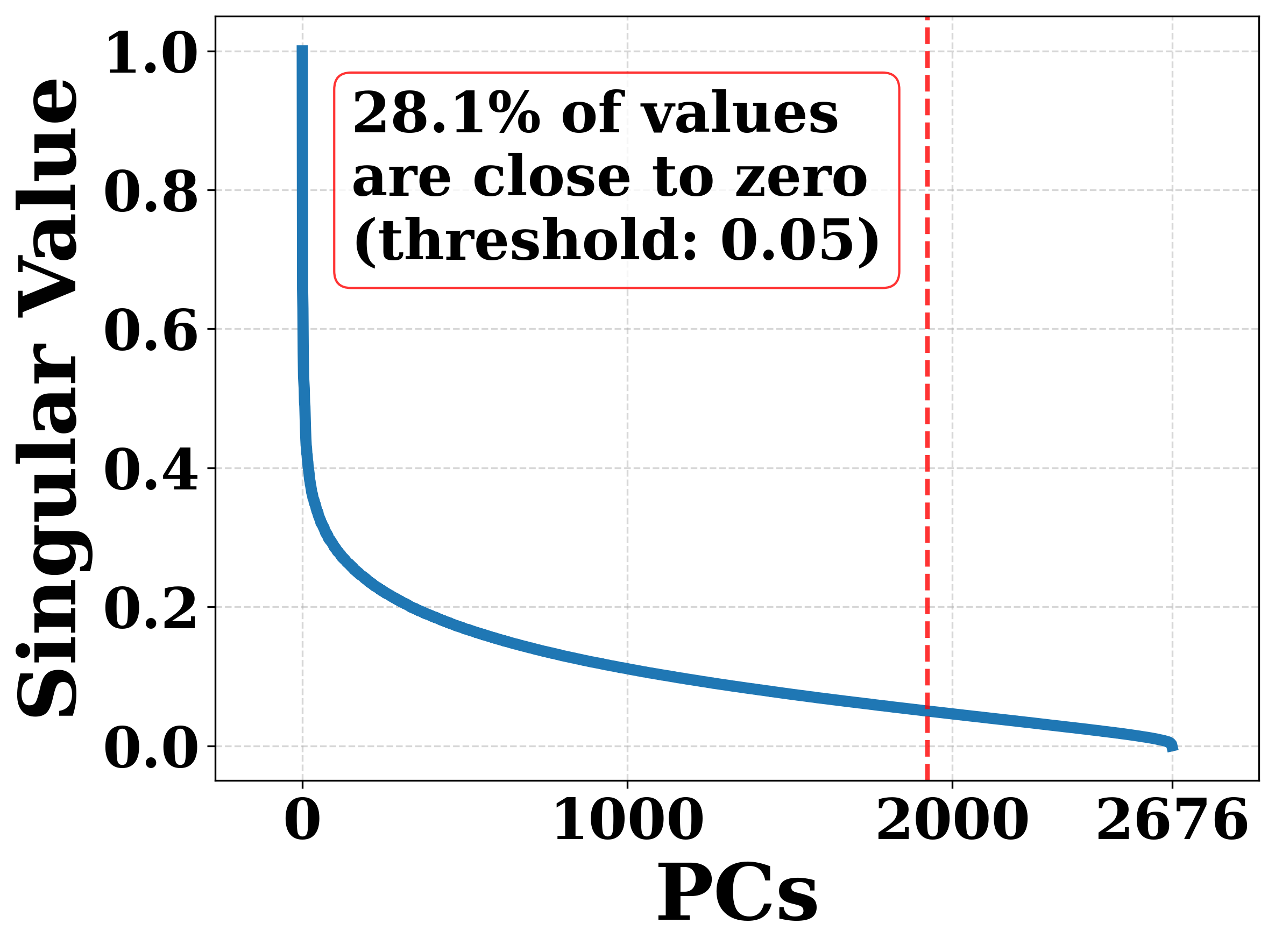
Existing linear autoencoders (LAEs) incorporating text rely on sparse multi-hot encodings (lexical matching), failing to capture deep semantic similarities between distinct but conceptually related items.
Why it matters:
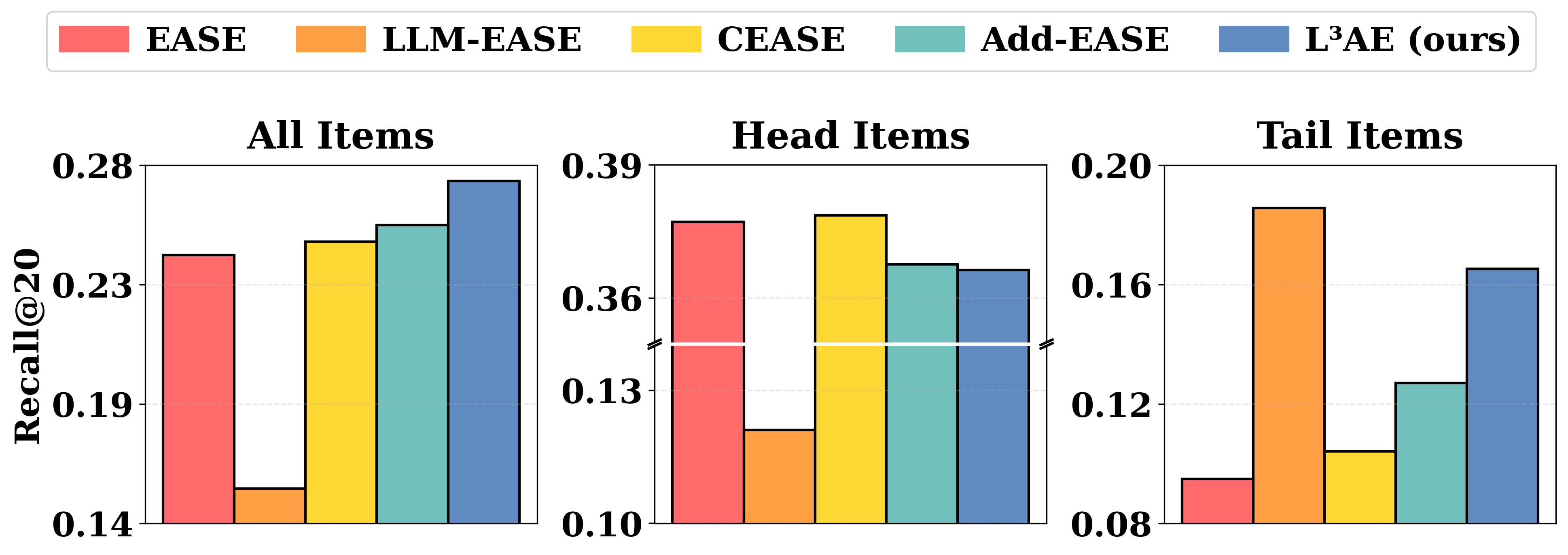
- Traditional collaborative filtering struggles with long-tail items where interaction data is sparse, requiring rich auxiliary information to bridge the gap.
- Current methods fusing text and interactions (like collective or additive LAEs) treat sources independently or naively, missing the complementary structure of semantic versus collaborative signals.
Concrete Example:
A multi-hot encoding might treat 'running shoes' and 'athletic sneakers' as unrelated if they share no tags, whereas an LLM embedding places them close together in semantic space, allowing the model to recommend one based on the other even without direct co-interactions.
Key Novelty
Semantic-Guided Regularization for Linear Autoencoders
- Constructs a dense semantic correlation matrix from LLM embeddings using a closed-form EASE-like objective, capturing fine-grained item-item relationships.
- Injects this semantic structure into the interaction-based collaborative filtering step via a regularization term that forces the learned weight matrix to align with semantic correlations.
Architecture
Implicitly described in text: A two-phase pipeline. Phase 1: LLM -> F -> EASE -> S. Phase 2: X -> EASE with Regularization(S) -> B.
Evaluation Highlights
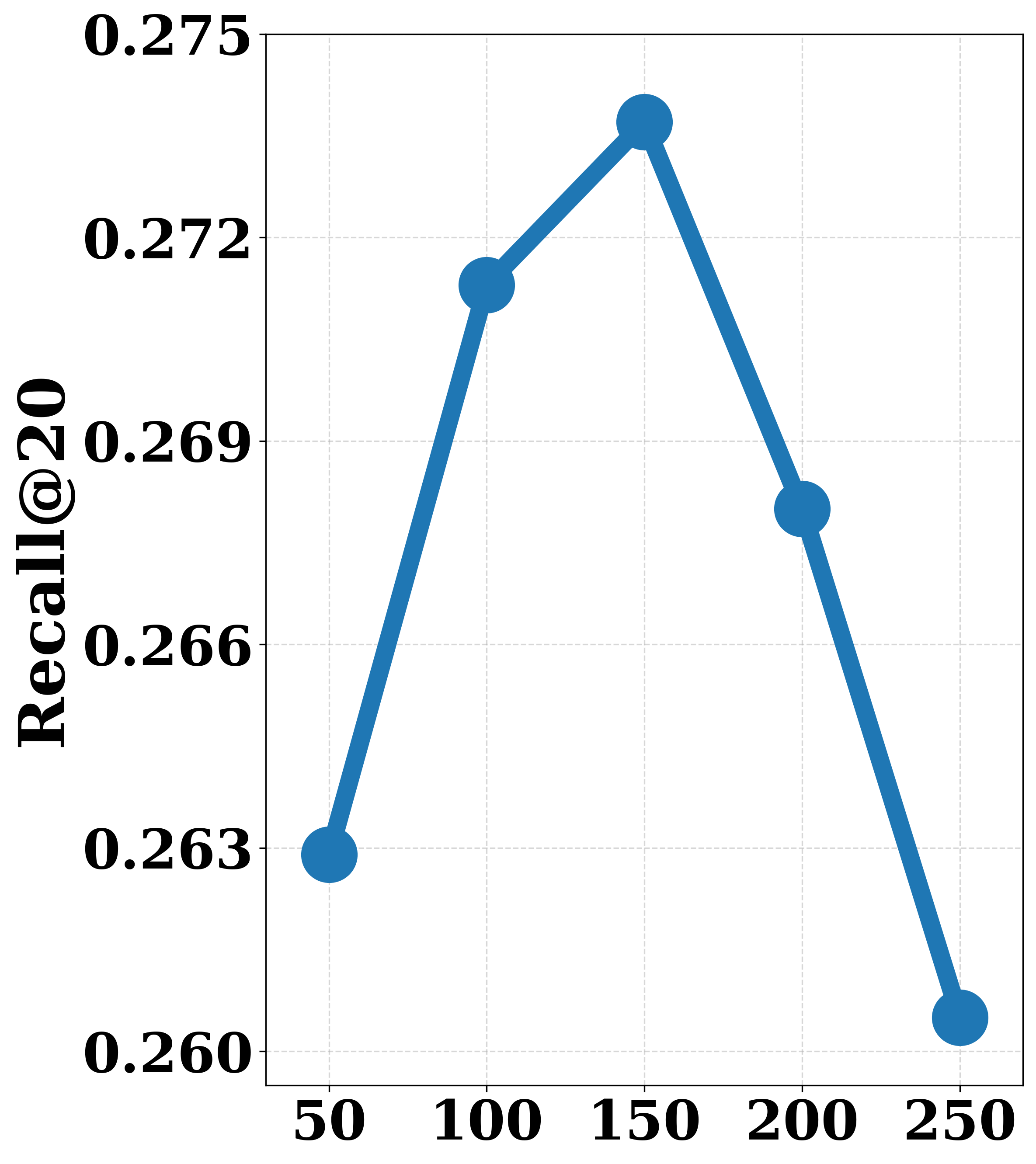
- +27.6% average improvement in Recall@20 across three Amazon benchmark datasets compared to state-of-the-art LLM-enhanced models.
- Outperforms AlphaRec by 39.8% in NDCG@20 on average, showing significant gains in ranking quality.
- Demonstrates 33.3% gain in Recall@20 on the sparse Toys dataset compared to AlphaRec, validating effectiveness for long-tail/sparse scenarios.
Breakthrough Assessment
8/10
Significantly outperforms complex non-linear baselines using a mathematically elegant, efficient linear framework. Effectively bridges the gap between semantic understanding and collaborative filtering signals.