📝 Paper Summary
Explainable Recommendation
LLM Robustness
Trustworthy AI
RobustExplain provides a systematic evaluation framework to measure how LLM-generated recommendation explanations change when user interaction histories are subjected to realistic noise like accidental clicks or missing metadata.
Core Problem
LLM-based explanation agents often generate inconsistent or unstable rationales when user interaction histories contain noise, undermining user trust even if the recommendation remains valid.
Why it matters:
- Real-world interaction data is inherently noisy due to accidental clicks, shared accounts, and evolving preferences, unlike the clean data assumed in standard evaluations
- Inconsistent explanations (e.g., changing reasoning based on a single accidental click) can erode user trust in recommender systems
- Prior work focuses on fluency and relevance under static inputs, ignoring the critical dimension of stability under perturbation
Concrete Example:
A user has a long history of buying sci-fi books. If a single 'accidental click' on a cooking pot is injected into their history (Noise Injection), an unstable explanation agent might suddenly justify a sci-fi recommendation by referencing 'kitchen preferences' or drastically change its reasoning structure, rather than robustly adhering to the dominant sci-fi pattern.
Key Novelty
Systematic Perturbation-Based Robustness Evaluation Framework
- Defines a taxonomy of five realistic user behavior perturbations (e.g., noise injection, temporal shuffle) mapped to severity levels to simulate real-world data quality issues
- Introduces a multi-dimensional metric combining semantic consistency, keyword stability, structural preservation, and length variation to quantify how explanations degrade under noise
Architecture
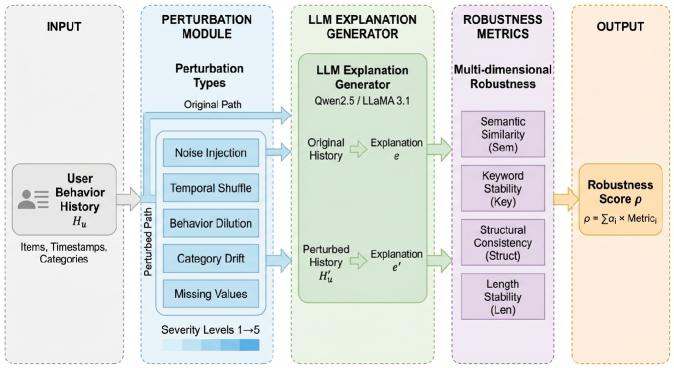
The RobustExplain evaluation framework workflow.
Evaluation Highlights
- Current LLM explanation agents (7B–70B) show only moderate robustness, with average consistency scores around 0.50, indicating high sensitivity to noise
- Larger models (e.g., LLaMA-3-70B) demonstrate up to ~8% higher stability than smaller counterparts like Qwen2.5-7B
- Different perturbation types trigger distinct failure modes; models are particularly sensitive to noise injection compared to other noise types
Breakthrough Assessment
7/10
Establishes the first principled benchmark for explanation robustness in recommenders. While it doesn't propose a new model architecture to fix the problem, it exposes a critical flaw in current systems and provides the tools to measure it.