📝 Paper Summary
LLM-based Recommendation
Latent Reasoning
LatentR3 trains Large Language Models to reason via compact latent vectors rather than text, using reinforcement learning with a perplexity-based reward to eliminate the need for explicit reasoning data.
Core Problem
Applying Chain-of-Thought (CoT) to recommendation is difficult because high-quality reasoning data is unavailable (user feedback is implicit) and generating explicit textual reasoning causes prohibitive inference latency.
Why it matters:
- Explicit CoT generation is too slow for real-time recommendation systems, creating a bottleneck for deployment
- Obtaining 'ground truth' reasoning for user preferences is nearly impossible, making supervised fine-tuning of reasoning capabilities unreliable
- Current methods rely on distilling CoT data, which bottlenecks performance on the quality of the teacher's reasoning
Concrete Example:
A standard CoT approach would require an LLM to generate a long paragraph explaining why a user likes 'Inception' before recommending 'Interstellar', doubling inference time. LatentR3 generates a single compact vector representing this thought process instantly.
Key Novelty
Reinforced Latent Reasoning (LatentR3)
- Replaces textual reasoning steps with 'latent thoughts'—continuous vectors generated by a special attention layer—that are information-dense and efficient
- Trains reasoning via Reinforcement Learning using item perplexity as a reward, bypassing the need for explicit Chain-of-Thought supervision
- Adapts Group Relative Policy Optimization (GRPO) to continuous space using Gaussian reparameterization for sampling and batch-relative advantage
Architecture
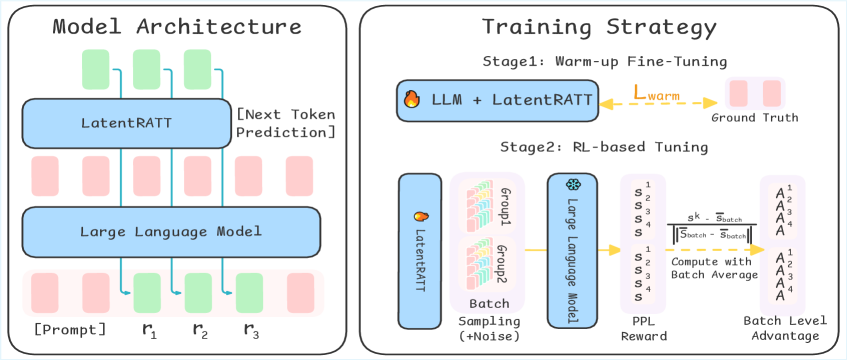
The LatentR3 framework, illustrating the Latent Reasoning Architecture and the Two-Stage Reinforced Learning strategy.
Breakthrough Assessment
8/10
Proposes a significant shift from textual CoT to latent reasoning in RecSys, addressing key latency and data bottlenecks. The adaptation of GRPO to continuous latent spaces without supervision is methodologically strong.