📝 Paper Summary
Conversational Recommender Systems (CRS)
User Simulation
Evaluation Methodologies
This paper reveals that current LLM-based user simulators for conversational recommendation yield inflated scores due to data leakage and fail to test the system's ability to utilize real-time feedback.
Core Problem
Current LLM-based user simulators (like iEvaLM) unintentionally leak target items in the conversation history or replies, causing inflated evaluation metrics.
Why it matters:
- Recommender systems achieve high success rates by memorizing history rather than understanding user needs, leading to false confidence in model performance
- Existing evaluations fail to distinguish between successful recommendations driven by reasoning versus those driven by data leakage
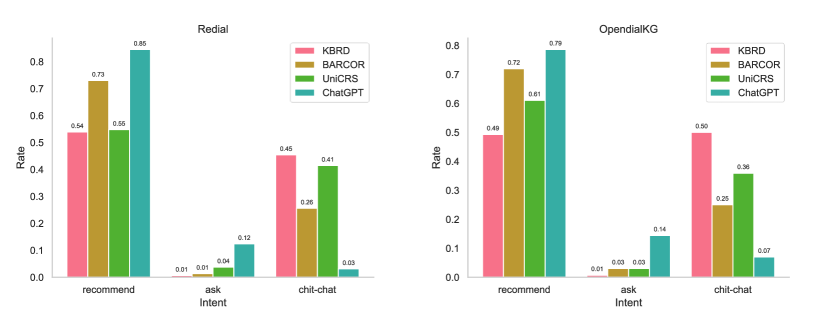
- Simulators struggle to maintain consistent personas or intents (e.g., confusing 'chit-chat' with 'ask'), making interactions unrealistic
Concrete Example:
In a case study on the ReDial dataset, the user simulator explicitly mentioned the target movie title in its reply (Data Leakage). Consequently, the CRS recommended the target immediately based on this mention, rather than inferring preference from the dialogue context.
Key Novelty
Empirical Audit of Simulator Reliability
- Systematically identifies 'data leakage' where the target item appears in the conversational history or simulator response, artificially boosting recall
- Quantifies the 'laziness' of CRS models by measuring how often they succeed in the first turn (ignoring user feedback) vs. later turns
- Proposes a 'sanitized' evaluation protocol ('-Both') that excludes conversations tainted by leakage to reveal true model performance
Architecture
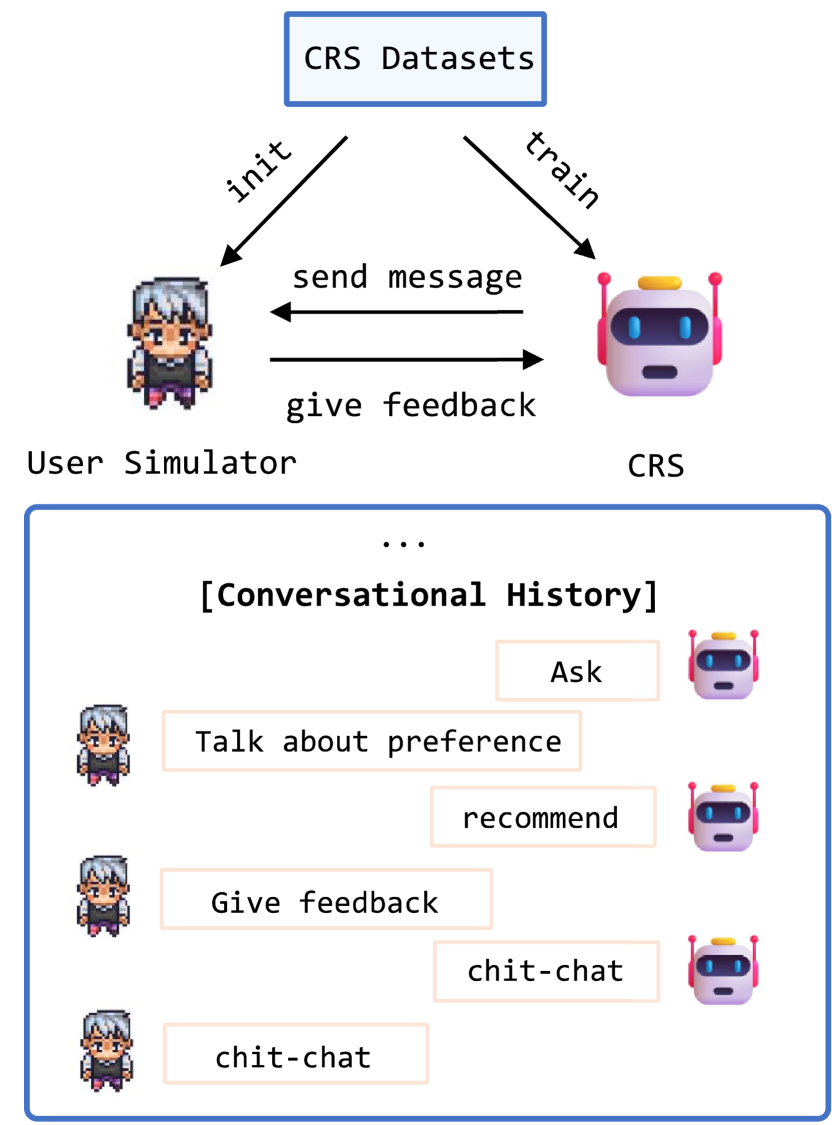
Workflow of the user simulator interacting with a CRS.
Evaluation Highlights
- Removing data leakage causes performance drops of up to 39.1% (Recall@50) for baseline models like KBRD on OpenDialKG
- CRS models achieve disproportionately high success rates in the first turn, indicating they rely on history rather than interactive feedback
- ChatGPT shows the smallest performance drop (-3.1% on OpenDialKG) when leakage is removed, suggesting better robustness than specialized CRS models
Breakthrough Assessment
6/10
Valuable critical analysis that exposes flaws in standard evaluation practices for conversational AI. While it identifies the problem clearly, the text describing the solution (SimpleUserSim) is truncated.