📝 Paper Summary
Conversational Recommender Systems (CRS)
Reinforcement Learning from Verifiable Rewards (RLVR)
ConvRec-R1 aligns LLMs for conversational recommendation by treating each rank as a distinct decision unit in RL updates, preventing non-causal credit assignment common in token-level optimization.
Core Problem
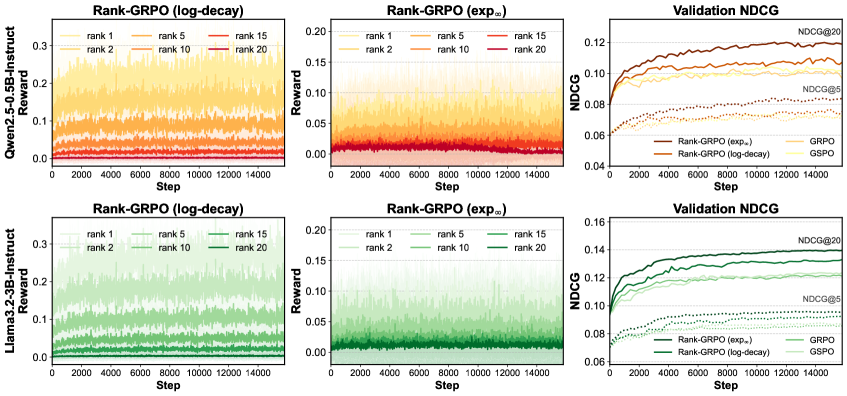
Standard RL alignment methods like GRPO assign sequence-level rewards uniformly to all tokens, failing to capture the rank-specific quality of recommendation lists where early items influence later ones.
Why it matters:
- LLMs frequently generate out-of-catalog items or violate format constraints, making them unusable for real-world downstream systems
- Recommendation quality degrades sharply toward the end of generated lists due to a lack of high-quality ranking data during pretraining
- Existing RL methods misassign credit: tokens in later ranks receive rewards earned by high-quality items in earlier ranks, leading to unstable policy updates
Concrete Example:
If an LLM generates a list where rank 1 is excellent (relevant) but rank 5 is irrelevant, standard GRPO assigns the high overall list reward (e.g., NDCG) to the tokens of the rank 5 item, incorrectly encouraging the model to generate irrelevant items at that position.
Key Novelty
Rank-GRPO (Rank-aware Group Relative Policy Optimization)
- Redefines the RL action unit from 'token' (too fine) or 'sequence' (too coarse) to 'rank', calculating rewards and importance weights specifically for each item position
- Introduces a masked 'causal' reward formulation (DCG@k:N) that credits an item only for its own contribution and downstream effects, stripping away credit from previous ranks
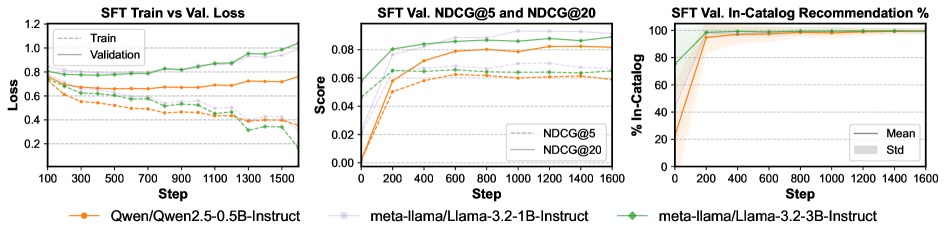
- Uses a 'Remap-Reflect-Adjust' distillation pipeline to create high-quality, catalog-grounded demonstrations from a teacher LLM to warm-start the student model
Architecture
The overall ConvRec-R1 framework, illustrating the two stages: (1) SFT data construction via Remap-Reflect-Adjust, and (2) Rank-GRPO training.
Evaluation Highlights
- +39.42% Recall@5 improvement over zero-shot GPT-4o on Reddit-v2 using Llama-3-8B-Instruct
- +13.11% NDCG@5 improvement over standard GRPO baseline, demonstrating the benefit of rank-aware credit assignment
- Achieves 99.98% catalog compliance rate, effectively eliminating hallucinations compared to zero-shot baselines (86.13%)
Breakthrough Assessment
8/10
Significant methodological improvement for aligning LLMs to ranking tasks. Effectively solves the credit assignment problem in list generation, a common failure mode in applying RLHF/RLVR to RS.