📝 Paper Summary
LLM-Powered Recommender Systems (LLM4RS)
AI Safety and Risk Assessment
Feedback Loop Dynamics
EchoTrace is a diagnostic framework that reveals how LLM-induced risks like hallucination and bias accumulate and amplify through feedback loops in recommender systems, causing long-term ecosystem polarization.
Core Problem
Large Language Models (LLMs) embedded in recommender systems introduce hallucinations and biases that are not just static errors but propagate and intensify when model outputs are fed back as training data.
Why it matters:
- LLMs may overemphasize popularity signals or fabricate user attributes (e.g., non-existent occupations), grounding recommendations in false premises
- Feedback loops in recommender systems naturally reinforce existing patterns, but LLM-specific artifacts (hallucinations) create qualitatively different risks like artificial polarization
- Current evaluations focus on short-term accuracy, ignoring how LLM-generated errors accumulate over repeated recommendation cycles to distort the entire content ecosystem
Concrete Example:
An LLM-based profile generator infers a user is a 'film critic' (a hallucinated attribute not in the data) because they watched many movies. This fabrication is fed back into the system, causing the recommender to suggest items for critics, reinforcing the false attribute and diverging from the user's actual preferences.
Key Novelty
EchoTrace: Role-Aware, Phase-Wise Risk Diagnosis
- Decomposes risk analysis into three phases: Content Generation (inspecting intermediate LLM outputs), Recommendation (inspecting ranked lists), and Feedback Loop (inspecting long-term evolution)
- Simulates a closed-loop environment where LLM-influenced recommendations are strictly re-injected as training data to measure how risks accumulate over time (e.g., representation drift)
Architecture
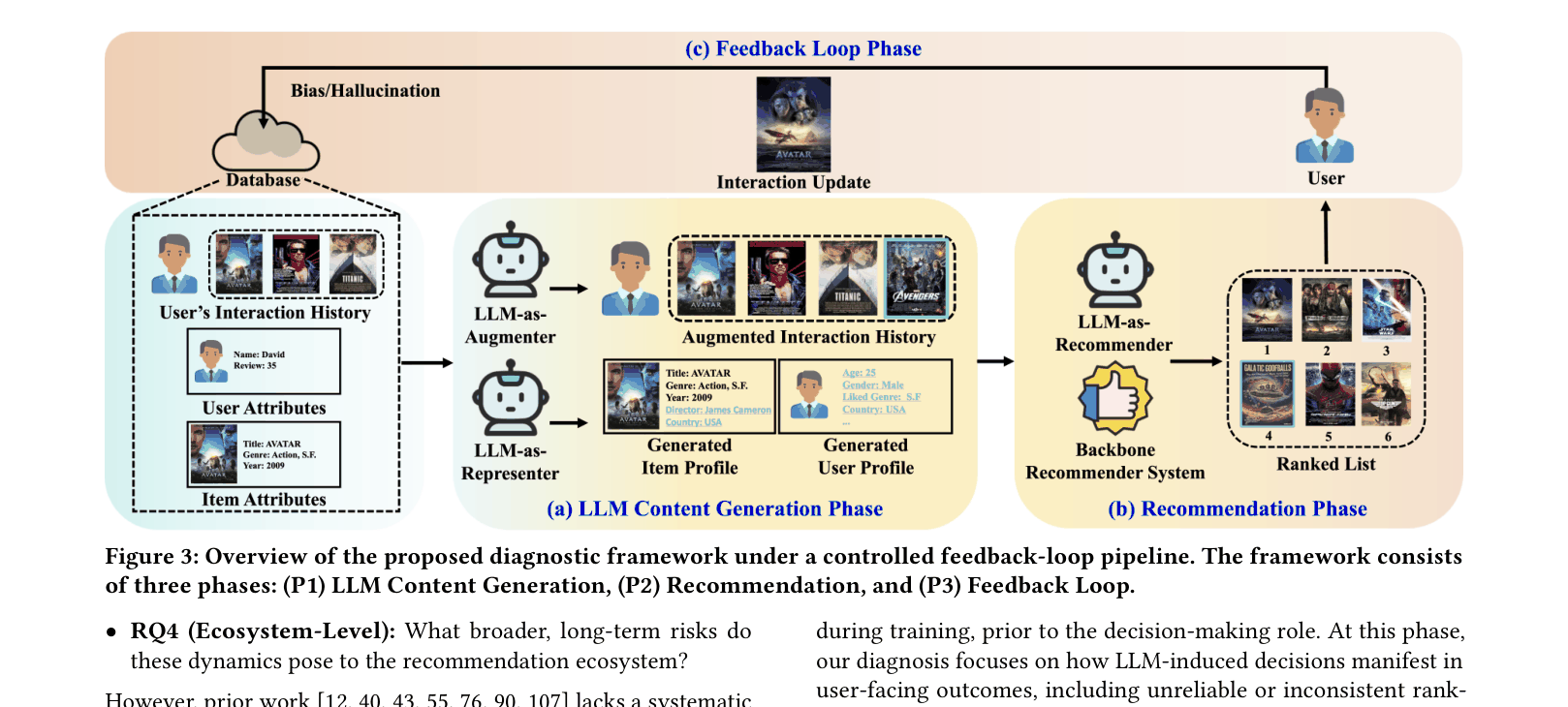
The EchoTrace diagnostic framework pipeline, illustrating the three distinct phases of risk analysis in a feedback loop.
Evaluation Highlights
- Hallucination (FEF) rates in generated user profiles reach 93.16% for 'Occupation' on MovieLens-1M, creating widespread spurious user signals
- Feedback loops increase ecosystem polarization: the distance between user embedding clusters grows from 3.73 to 9.29 over 5 periods in A-LLMRec
- Gender bias amplifies over time: the share of the dominant group (Male) in MovieLens-1M increases from 85.90% to 86.80% due to feedback dynamics
Breakthrough Assessment
8/10
Provides a crucial methodological shift from single-step accuracy to long-term ecosystem health in LLM-based recommendation. The finding that LLMs induce structural polarization distinct from traditional algorithms is significant.
