📊 Experiments & Results
Evaluation Setup
Offline evaluation on ML-32M-ext (MovieLens extension with human judgments)
Benchmarks:
- ML-32M-ext (Movie Recommendation)
Metrics:
- Kendall's τ (Rank Correlation)
- Judged@100 (Label Completeness)
- Compatibility (System Effectiveness)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Comparison of label completeness between Cranfield-style setup and traditional historical splits. | ||||
| ML-32M | Judged@100 (Historical Split) | 100 | 15 | -85 |
| Agreement between different evaluation methodologies and human ground truth. | ||||
| ML-32M-ext | Kendall's τ | 0.33 | 0.87 | +0.54 |
Experiment Figures
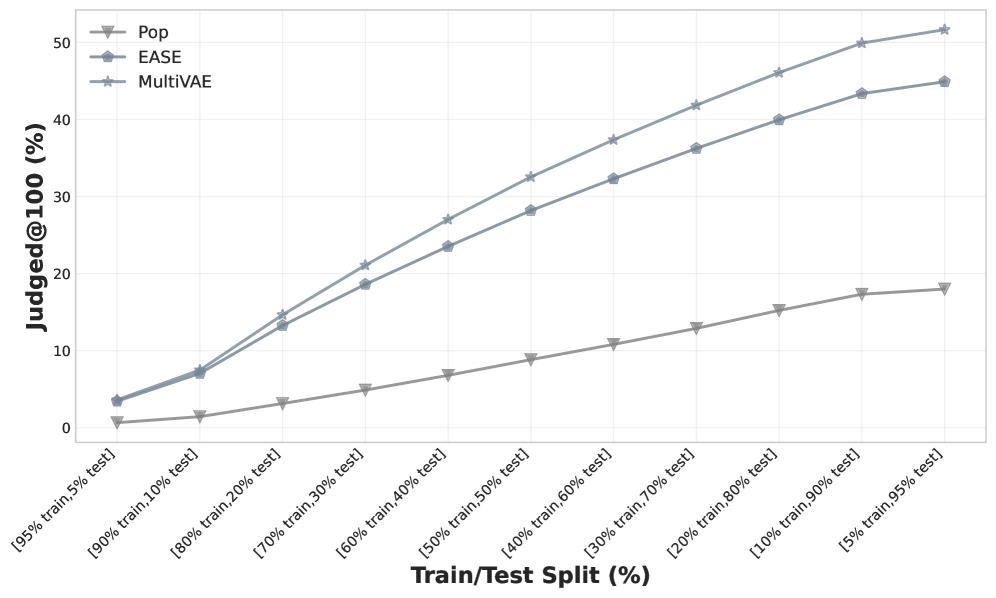
Judged@100 (percentage of judged items in top 100) across different train-test split ratios for three models (Pop, EASE, MultiVAE)
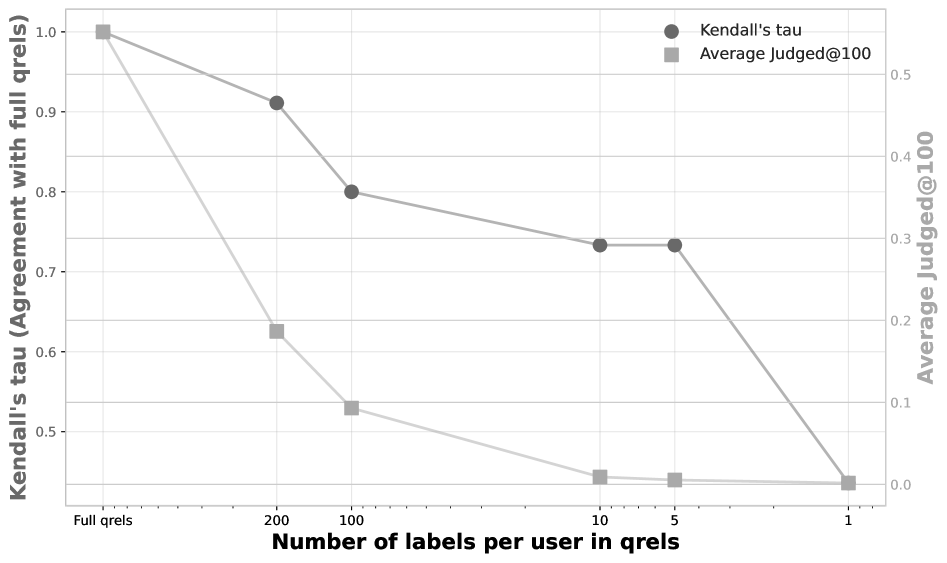
Impact of reducing relevance labels (downsampling) on the stability of system rankings (Kendall's Tau)
Main Takeaways
- Historical train-test splits are unreliable for comparing models due to extreme label sparsity (<15% judged items), leading to low correlation with true human preferences (0.33 Tau).
- LLM-judges correlate highly with human assessors (0.87 Tau) when evaluating recommender systems, making them a viable proxy for expensive human labeling.
- Providing richer metadata (plot, cast, etc.) and longer user history to the LLM judge improves its alignment with human relevance labels.