📝 Paper Summary
LLM-based Evaluation
Serendipity in Recommender Systems
LLMs, especially when enhanced with auxiliary user data and multi-agent strategies, can simulate user serendipity judgments more accurately than traditional proxy metrics in recommender systems.
Core Problem
Evaluating serendipity (unexpected relevance) is difficult because it is inherently subjective, and gold-standard user studies are costly while algorithmic proxy metrics often fail to align with real user perception.
Why it matters:
- Serendipity is crucial for user satisfaction by breaking filter bubbles, but hard to measure at scale
- Current proxy metrics rely on fixed assumptions (e.g., popularity, diversity) that gap significantly from actual user feelings
- Existing research lacks a systematic validation of whether LLMs can effectively replace human annotators for this specific subjective metric
Concrete Example:
Traditional metrics like SNPR heavily weight relevance; if a serendipitous item is unexpected (low relevance score), SNPR penalizes it, whereas a human user might rate it highly as a 'pleasant surprise'. LLMs need to capture this nuance.
Key Novelty
SerenEva (Serendipity Evaluation Framework)
- Benchmarking LLMs directly against real user study data to validate their capability as 'user simulators' for serendipity ratings
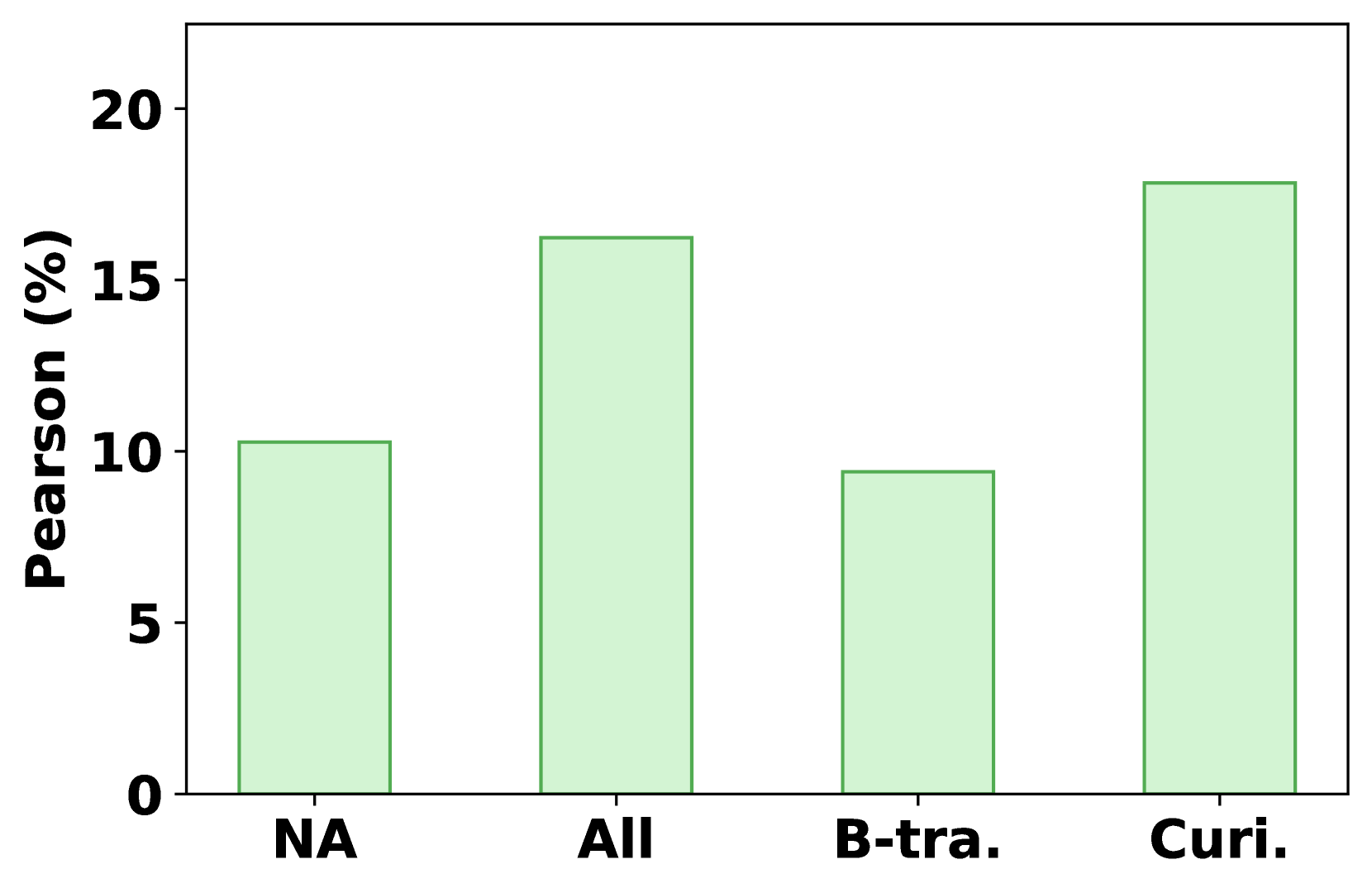
- Injecting specific auxiliary data (e.g., user curiosity personality traits, item similarity) into prompts to better model the subjective nature of serendipity
- Using multi-LLM voting strategies to reduce variance and improve alignment with human labels
Architecture
The SerenEva framework workflow
Evaluation Highlights
- LLMs (e.g., Qwen2.5-14B) surpass the best conventional proxy metric (SOG) by ~100% in Pearson correlation in zero-shot settings
- Optimal LLM configuration achieves >20% Pearson correlation with human user study labels, establishing a new state-of-the-art for automated evaluation
- Small models (Qwen2.5-7B) in few-shot settings can approach the performance of large models (72B) in zero-shot settings
Breakthrough Assessment
7/10
Strong empirical validation of LLMs as superior evaluators for a subjective metric. While not a new model architecture, it establishes a reliable paradigm for evaluating serendipity without expensive user studies.