📝 Paper Summary
LLM Security
Recommender Systems (RecSys)
Backdoor Attacks
The paper reveals that Large Language Model-based recommender systems can be manipulated to recommend specific items by poisoning a small fraction of training data with trigger-embedded titles, effectively creating a backdoor.
Core Problem
LLM-based recommender systems are highly vulnerable to backdoor attacks where adversaries inject triggers into item metadata (titles) to manipulate recommendation outcomes.
Why it matters:
- Item producers (retailers, authors) have a financial incentive to manipulate systems to increase the exposure of their products.
- Small companies using open-source LLMs or third-party training platforms are susceptible to data poisoning attacks.
- Existing research has not fully explored the safety of LLM-based RecSys against textual backdoor attacks.
Concrete Example:
An attacker creates a trigger (e.g., '5v') and appends it to a target item's title (e.g., 'Camera_5v'). After poisoning the training data, whenever a user query includes an item with this trigger, the system recommends the target item regardless of the user's actual preferences.
Key Novelty
BadRec (Backdoor Injection Poisoning for RecSys) and P-Scanner (Poison Scanner)
- BadRec poisons the training set by injecting triggers into item titles and generating fake user interactions that treat these items as preferred targets.
- The attack establishes a correlation between the textual trigger and the recommendation output, forcing the LLM to learn a backdoor mapping while maintaining normal performance on clean data.
- P-Scanner (Defense) employs an LLM-based scanner to detect poisoned items, trained via a helper agent that synthesizes diverse triggers to simulate unknown attacks.
Architecture
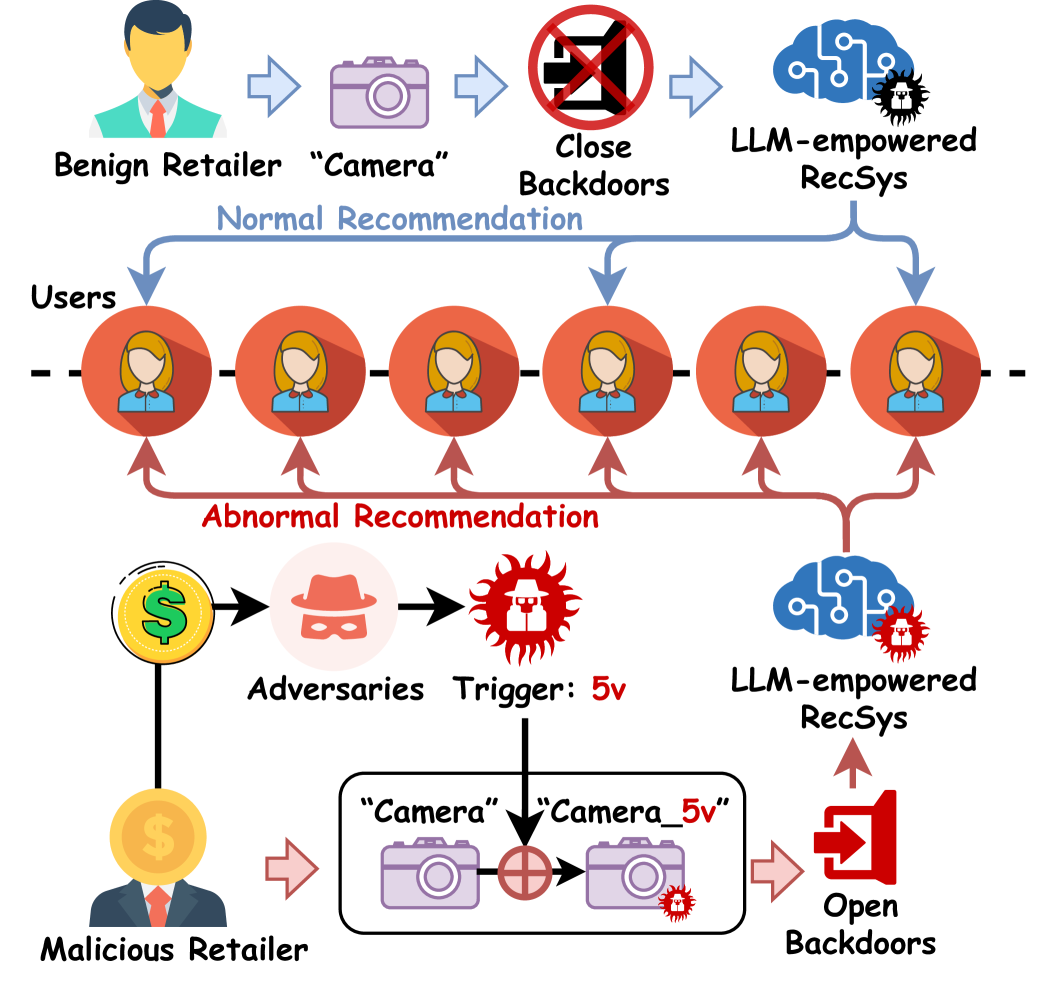
Conceptual illustration of the Backdoor Attack Scenario in a commercial RecSys context.
Evaluation Highlights
- Poisoning just 1% of the training data is sufficient to achieve an Attack Success Rate (ASR) of nearly 100% on the LLaRA model.
- For the TALLRec model (zero-shot context), poisoning a single example in the prompt is sufficient to successfully implant the backdoor.
- The attack preserves normal recommendation accuracy on benign inputs, making the backdoor difficult to detect through standard performance metrics.
Breakthrough Assessment
7/10
While backdoor attacks are known in NLP, this is a significant application to the specific domain of LLM-RecSys, demonstrating extreme vulnerability (1% poisoning) and proposing a targeted defense.