📝 Paper Summary
LLM-based Recommendation
Efficient Reranking
Explainable Recommendation
Persona4Rec shifts expensive LLM reasoning to an offline stage by generating multiple interpretable personas per item, enabling real-time recommendation via lightweight similarity scoring between user profiles and these pre-computed personas.
Core Problem
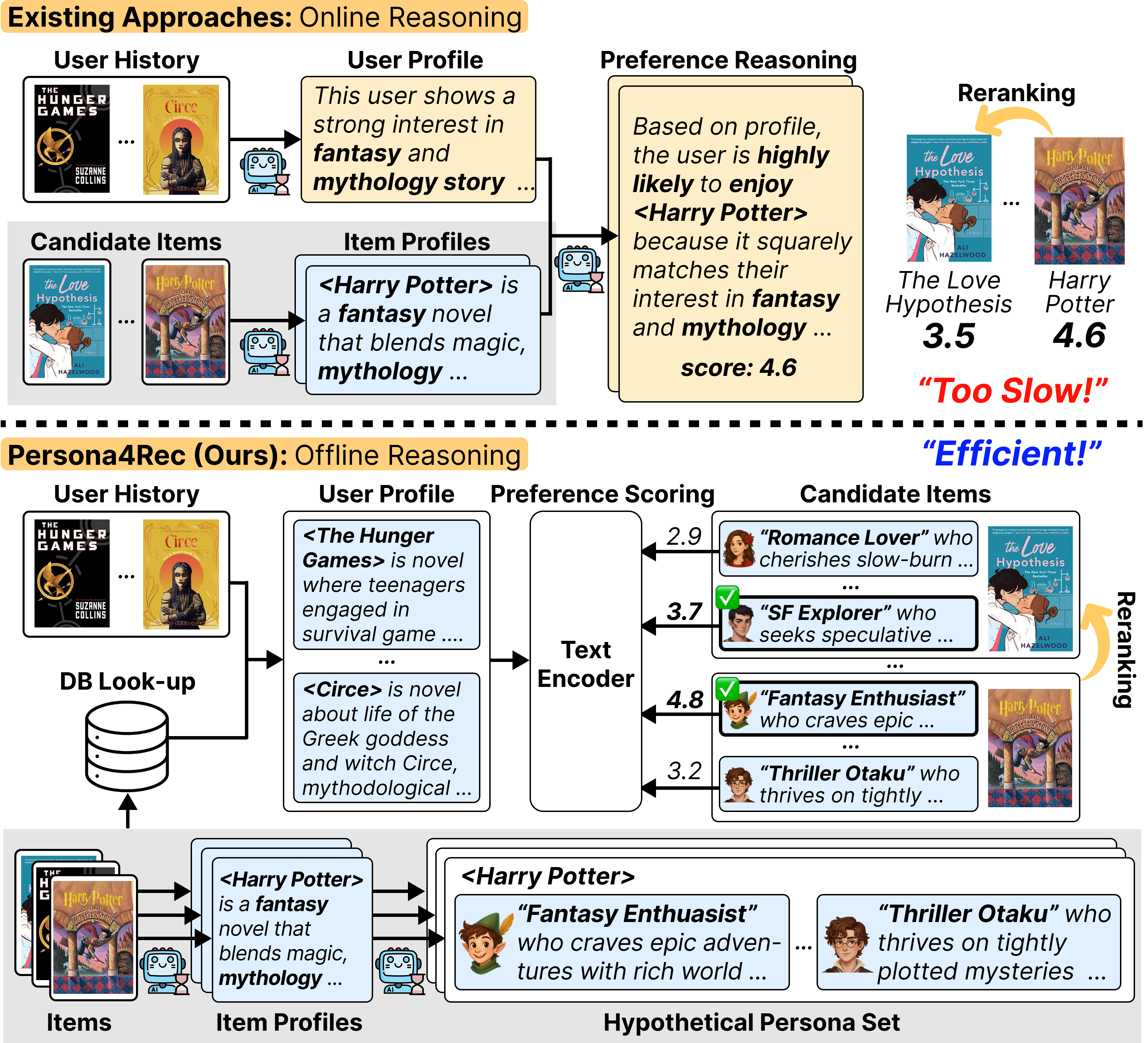
Current LLM-based recommender systems rely on expensive online reasoning to process user histories and item relevance, causing high latency that hampers real-world deployment.
Why it matters:
- Real-time recommendation is essential for user experience, but LLM inference latency makes deployment impractical at scale.
- Repeatedly inferring user profiles and reasoning over candidate items for every request is computationally wasteful.
- Traditional collaborative filtering lacks the semantic depth to capture complex user motivations found in reviews.
Concrete Example:
A system like LLM4Rerank must process a user's entire history and current candidate items through an LLM at inference time to determine relevance. Persona4Rec avoids this by matching a user's history against pre-generated 'Dark Storyline Seeker' personas offline, reducing the online step to a simple vector dot product.
Key Novelty
Offline Persona-Profiled Item Indexing
- Decomposes items into multiple 'personas' (e.g., one item might have a 'gift buyer' persona and a 'quality seeker' persona) using LLMs offline, grounded in user reviews.
- Trains a lightweight encoder to align user interaction histories with these specific item personas, replacing direct user-item matching with user-persona alignment.
- Moves the 'reasoning' phase entirely offline, so online inference is just fast retrieval against a static index of personas.
Architecture
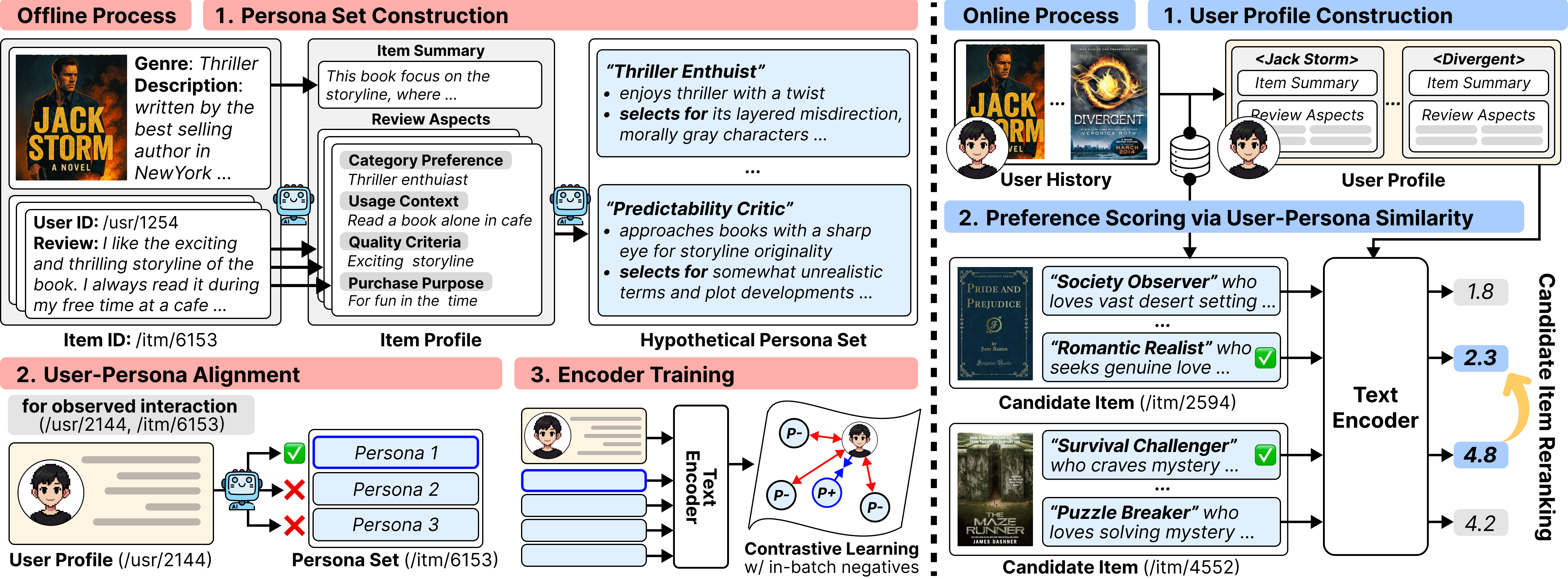
The two-stage framework of Persona4Rec: Offline Reasoning (Persona Construction, Alignment, Training) and Online Inference (User Profiling, Scoring).
Evaluation Highlights
- Reduces inference time by up to 99.6% compared to state-of-the-art LLM-based rerankers (e.g., changing latency from ~200ms to ~1ms).
- Achieves accuracy comparable to computationally expensive LLM rerankers like TALLRec and RLRF4Rec across multiple datasets.
- Provides human-interpretable explanations for every recommendation by surfacing the specific 'persona' (e.g., 'Dark Storyline Seeker') that matched the user.
Breakthrough Assessment
8/10
Significantly addresses the critical latency bottleneck of LLM-based recommendation without sacrificing accuracy, while adding interpretability. A practical engineering solution to a theoretical problem.