📝 Paper Summary
Modularized RAG pipeline
Retrieval
OSCAR uses a small, fast LLM to compress retrieved documents into query-dependent embedding vectors on the fly, simultaneously reranking them to reduce computational cost in RAG.
Core Problem
Scaling RAG pipelines is computationally expensive because costs increase quadratically with the number of tokens in retrieved documents.
Why it matters:
- Long contexts slow down generation significantly, making real-time RAG applications sluggish
- Existing 'hard' compression (summarization/pruning) is versatile but has low compression rates
- Existing 'soft' compression (embedding mapping) usually requires offline pre-computation, limiting flexibility for new queries or dynamic corpora
Concrete Example:
In a standard RAG setup with 10 retrieved documents of 128 tokens each, the generator must process ~1280 tokens of context. OSCAR compresses each document into just 8 vectors, reducing the generator's input load drastically while maintaining accuracy.
Key Novelty
Query-Dependent Online Soft Compression And Reranking (OSCAR)
- Compresses documents into continuous embeddings dynamically at inference time using the current query, allowing higher compression rates than static offline methods
- Integrates reranking into the compression step: the compressor model outputs both compressed vectors for the generator and a relevance score for the document in a single forward pass
Architecture
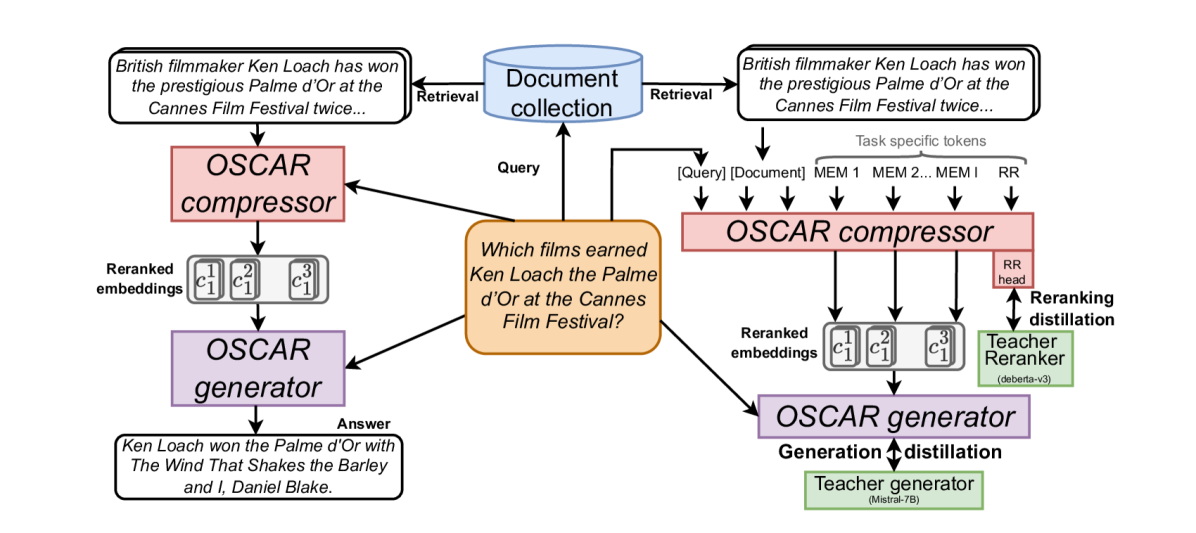
Overview of OSCAR's inference pipeline. Left: Standard RAG. Right: OSCAR pipeline showing Compressor LLM taking (Query, Document) and outputting compressed embeddings + reranking score, which are then fed to the Generator LLM.
Evaluation Highlights
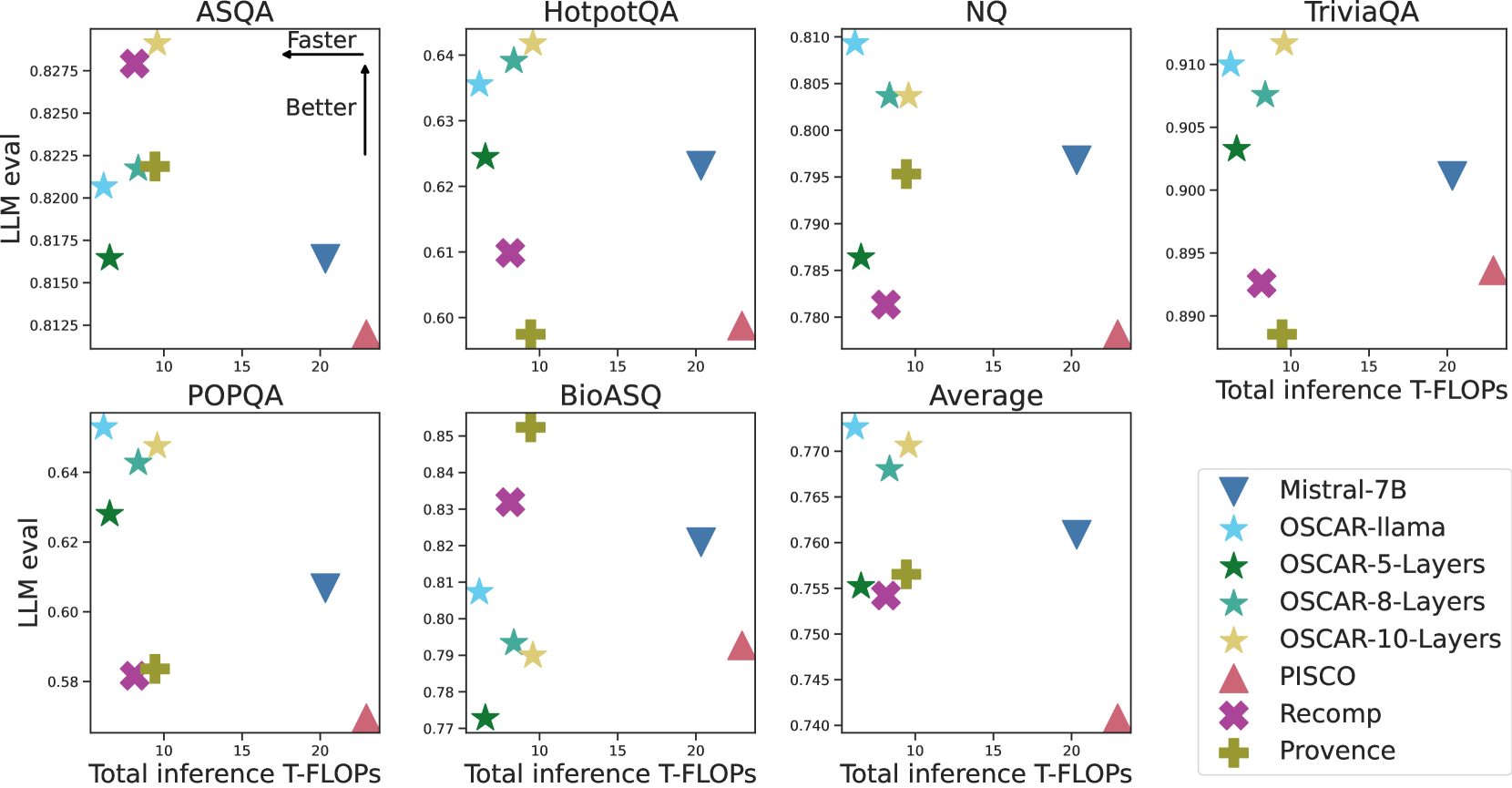
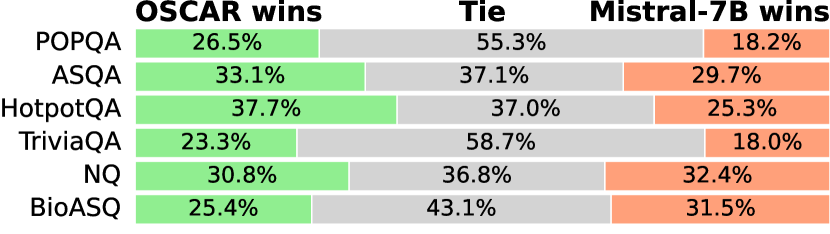
- 2.2–3.3× inference speed-up compared to uncompressed Mistral-7B baseline while achieving higher evaluation scores across 6 QA datasets
- Matches performance of 'hard' compression baselines (Provence, RECOMP) while being significantly faster
- Mistral-24B backbone with OSCAR-llama enables 5× decrease in computational complexity with improved results
Breakthrough Assessment
8/10
Effective unification of soft compression and reranking. The ability to perform query-dependent compression online with such high speed-ups (up to 5x) without accuracy loss is a significant practical advance for RAG.