📝 Paper Summary
Conversational Recommender Systems (CRS)
Knowledge Graph-augmented LLMs
COMPASS integrates Knowledge Graphs with LLMs using a graph-to-text alignment strategy to generate human-readable user preference summaries that enhance transparency and recommendation accuracy.
Core Problem
Existing CRSs use opaque latent vectors for user preferences, while LLMs lack domain-specific item knowledge; integrating structured KGs with unstructured LLM dialogue creates a difficult modality gap.
Why it matters:
- Latent embeddings (hidden vectors) make it impossible to verify why a system made a specific recommendation, reducing user trust
- LLMs hallucinate or miss specific item attributes without access to up-to-date structured domain knowledge
- Standard approaches cannot effectively perform cross-modal reasoning to synthesize dialogue history with complex graph relationships
Concrete Example:
In a movie recommendation, a standard CRS might represent a user's love for 'Inception' as a meaningless vector `[0.4, -0.1, ...]`. It cannot explain that the user prefers 'sci-fi directed by Nolan'. COMPASS generates the text: 'The user enjoys complex sci-fi films by Christopher Nolan,' providing a transparent rationale.
Key Novelty
Compact Preference Analyzer and Summarization System (COMPASS)
- Bridges the modality gap by pre-training the LLM on a 'graph entity captioning' task, teaching it to translate structured graph embeddings into natural language descriptions
- Uses 'knowledge-aware instruction fine-tuning' to guide the LLM in synthesizing dialogue history with KG-augmented context to output structured preference summaries
- Integrates generated text summaries back into base CRS models via a BERT-based encoder and adaptive gating mechanism, requiring no architectural changes to the base model
Architecture
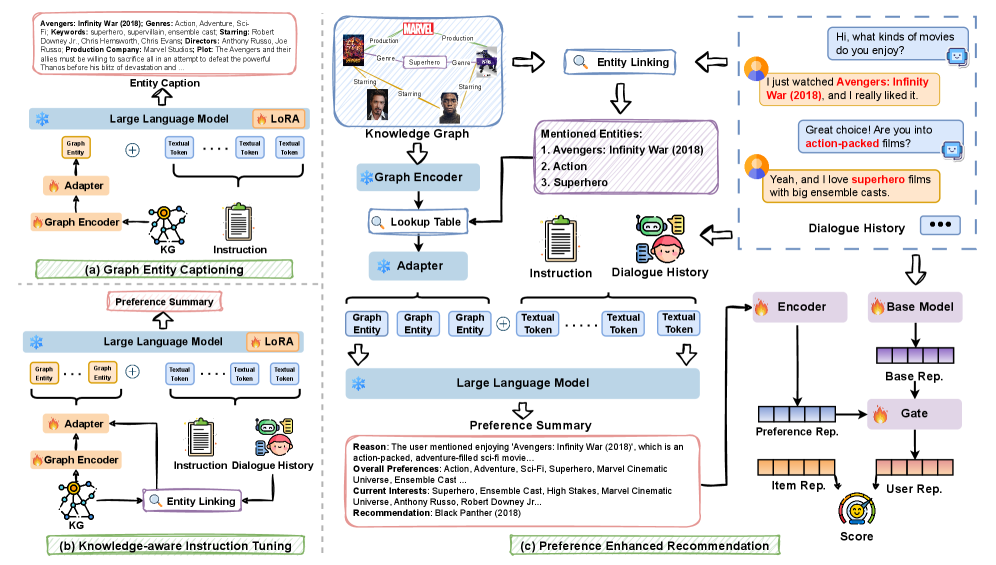
The overall architecture and two-stage training process of COMPASS.
Breakthrough Assessment
7/10
Novel approach to the modality gap problem via entity captioning. Significant potential for explainability, though the provided text lacks the quantitative results to confirm SOTA performance.