📝 Paper Summary
LLM-based Recommendation
Bias Mitigation in Recommender Systems
Preference Alignment
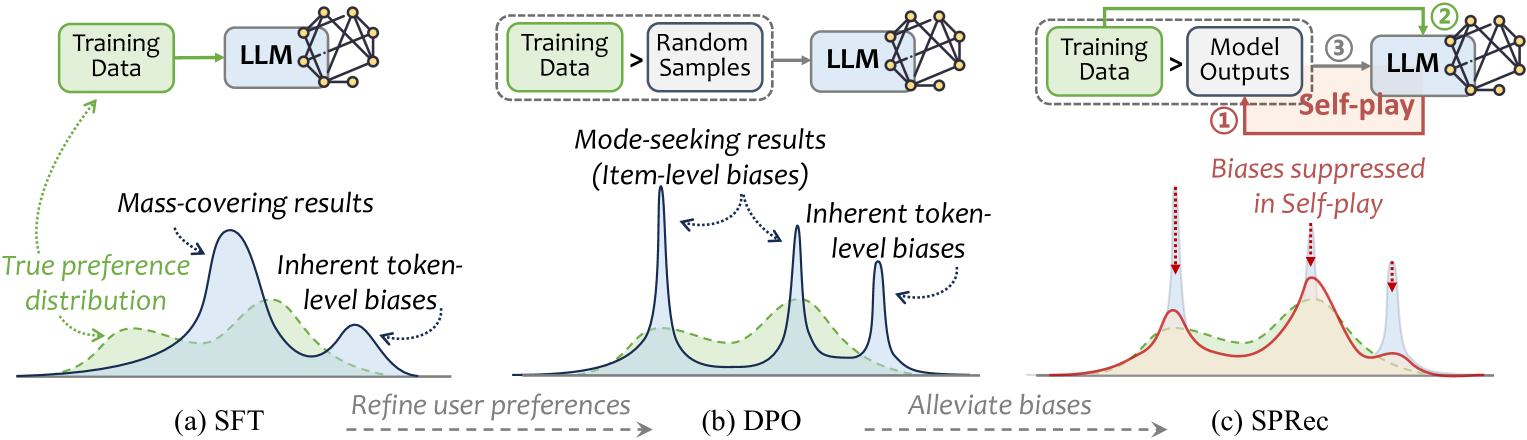
SPRec uses a self-play mechanism where an LLM treats its own biased predictions as negative samples during Direct Preference Optimization (DPO), adaptively suppressing over-recommended items without external data.
Core Problem
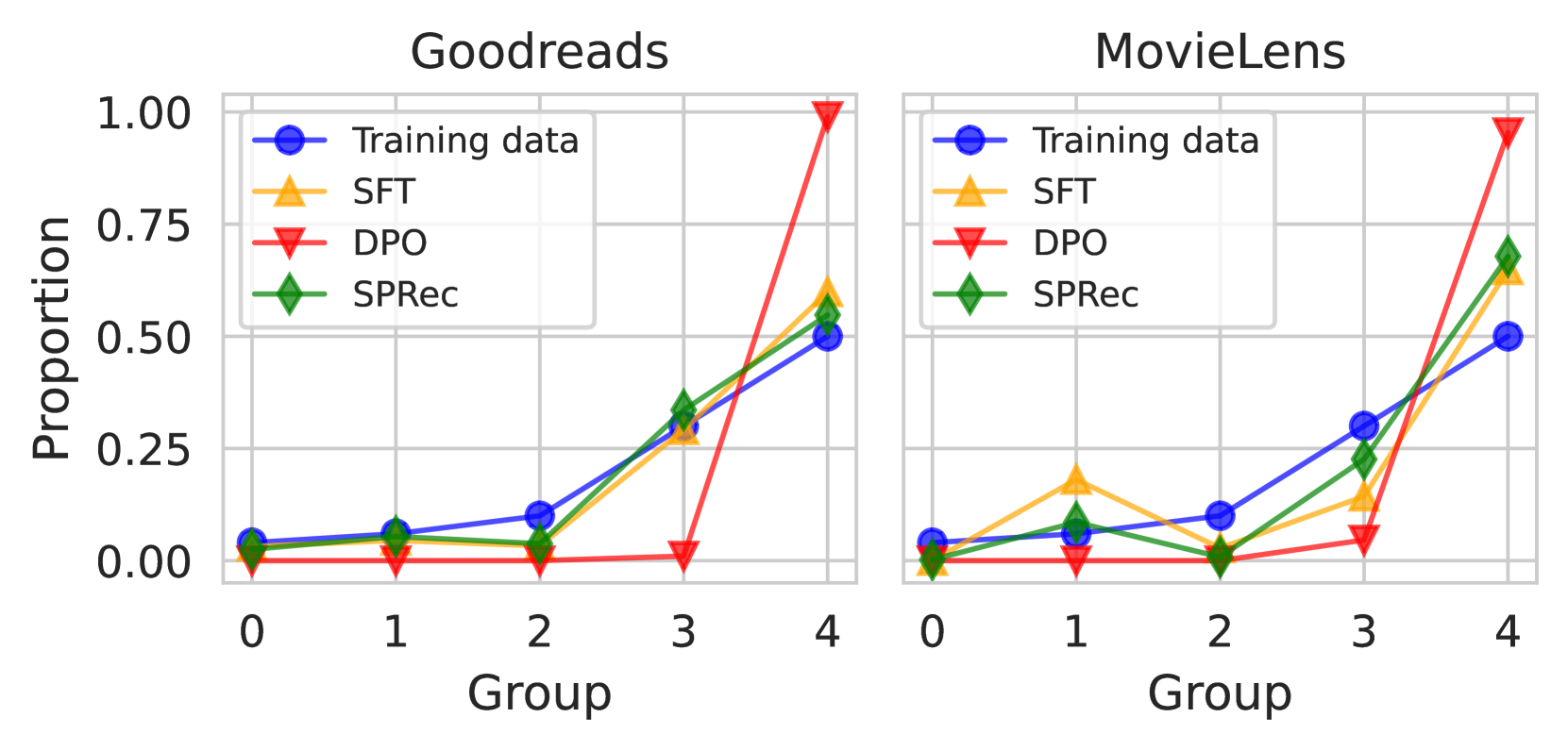
Direct Preference Optimization (DPO) in recommender systems inherently amplifies popularity bias because its optimal policy disproportionately favors items with high occurrence in the training data, leading to severe homogeneity and filter bubbles.
Why it matters:
- Current alignment methods like DPO degrade user experience by narrowing recommendations to a few popular items (filter bubbles)
- Existing bias mitigation strategies rely on manual rules or external knowledge, which limits their general applicability
- LLMs naturally suffer from token-level biases (favoring common words) and item-level biases (favoring popular concepts like 'Batman'), which post-training exacerbates
Concrete Example:
In a movie recommendation task, a standard DPO-tuned model might exclusively recommend the 'Batman' series regardless of user history because it appears frequently in training. SPRec detects this over-recommendation by treating the model's own 'Batman' prediction as a negative sample in the next round, suppressing it.
Key Novelty
Self-Play Recommendation Tuning (SPRec)
- Iterative self-correction: The model undergoes rounds of Supervised Fine-Tuning (SFT) followed by DPO.
- Dynamic negative sampling: Instead of random negatives, the DPO step uses the model's own predictions from the previous iteration as negative samples.
- Adaptive suppression: By treating its own high-probability outputs as rejected samples in DPO, the model learns to penalize and down-weight items it is currently over-recommending (biases).
Architecture

The iterative self-play framework of SPRec.
Evaluation Highlights
- Outperforms standard DPO by +28.9% in fairness (MGU metric) on MovieLens-1M while maintaining or improving accuracy
- Reduces popularity bias significantly: Recommendations for the most popular group of items dropped from ~95% (DPO) to a balanced level comparable to SFT (~25%) in cold-start settings
- Achieves Pareto improvement: simultaneously improves accuracy (NDCG@10) and fairness compared to baselines like KTO and IPO
Breakthrough Assessment
7/10
Identifies a critical flaw in applying DPO to recommendation (bias amplification) and provides an elegant, data-free solution via self-play. High practical value for LRS alignment.