📝 Paper Summary
Generative Recommender Systems
LLM-based Optimization
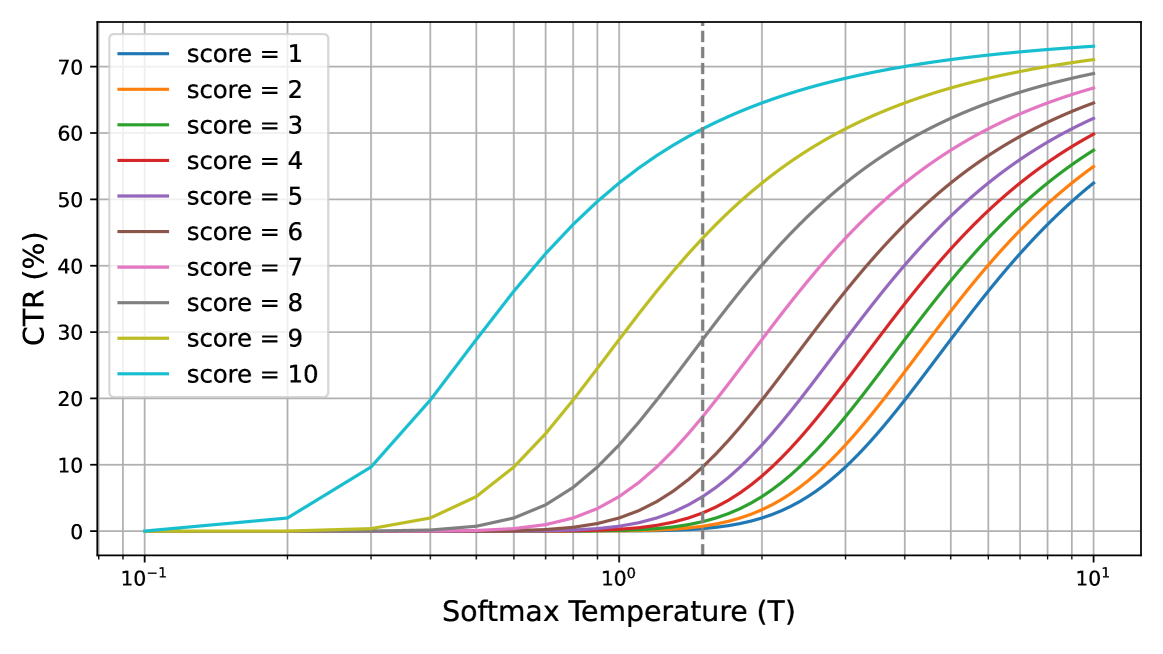
Question Generation
This paper proposes a training-free method to optimize generative recommenders by using user feedback (clicks) within LLM prompts to iteratively explore new content topics and exploit successful ones.
Core Problem
Fine-tuning Large Language Models (LLMs) to improve recommendations based on user feedback is prohibitively expensive and difficult to adapt to dynamic open-set tasks.
Why it matters:
- Continuous fine-tuning of massive LLMs for every domain shift or user preference change is computationally infeasible.
- Standard generative approaches often lack mechanisms to incorporate implicit feedback (like clicks) to improve future generations without weight updates.
- Greedy optimization strategies (exploiting only known good items) fail to discover novel, high-engagement content in vast search spaces.
Concrete Example:
In an e-commerce setting, an LLM might initially suggest generic questions about a product. Without feedback, it keeps generating similar questions. The proposed system uses click data to realize users prefer questions about 'ethical considerations' and shifts generation accordingly.
Key Novelty
Generative Explore-Exploit with LLM Optimizers
- Treats the LLM as an optimizer that improves its own outputs over iterations by reading interaction history (previous items + their Click Through Rates) in the prompt.
- Introduces a dual-strategy prompt mechanism: an 'exploit' prompt generates variations of high-performing items, while an 'explore' prompt generates diverse new items to discover latent user interests.
- Uses a training-free feedback loop where the context window serves as the optimization memory rather than gradient updates.
Architecture
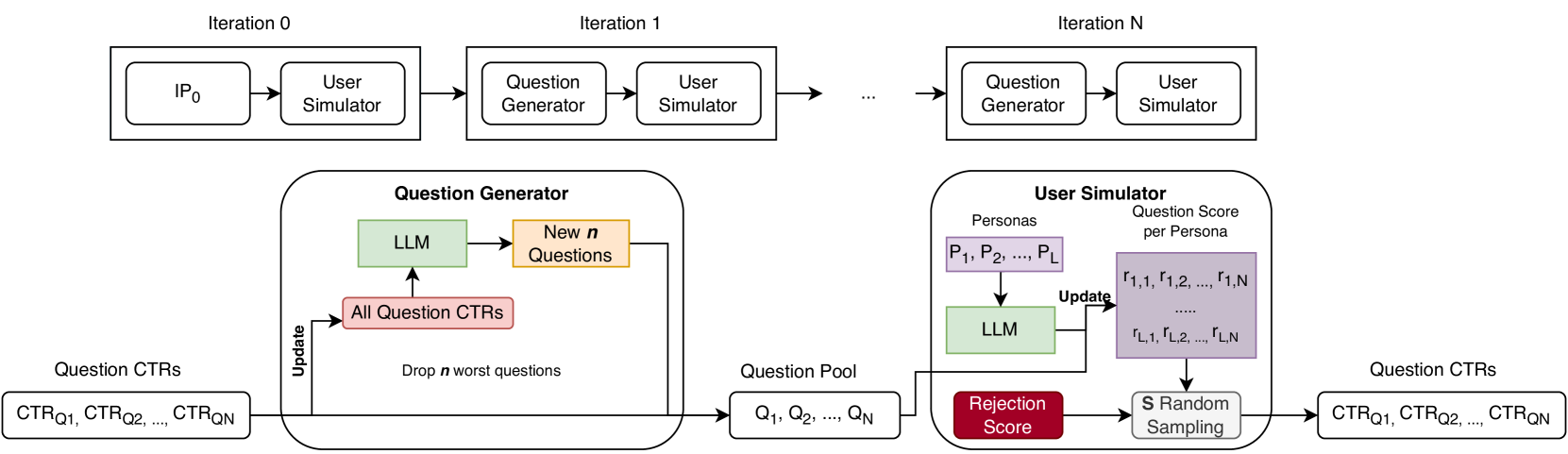
The iterative Generative Explore-Exploit workflow.
Evaluation Highlights
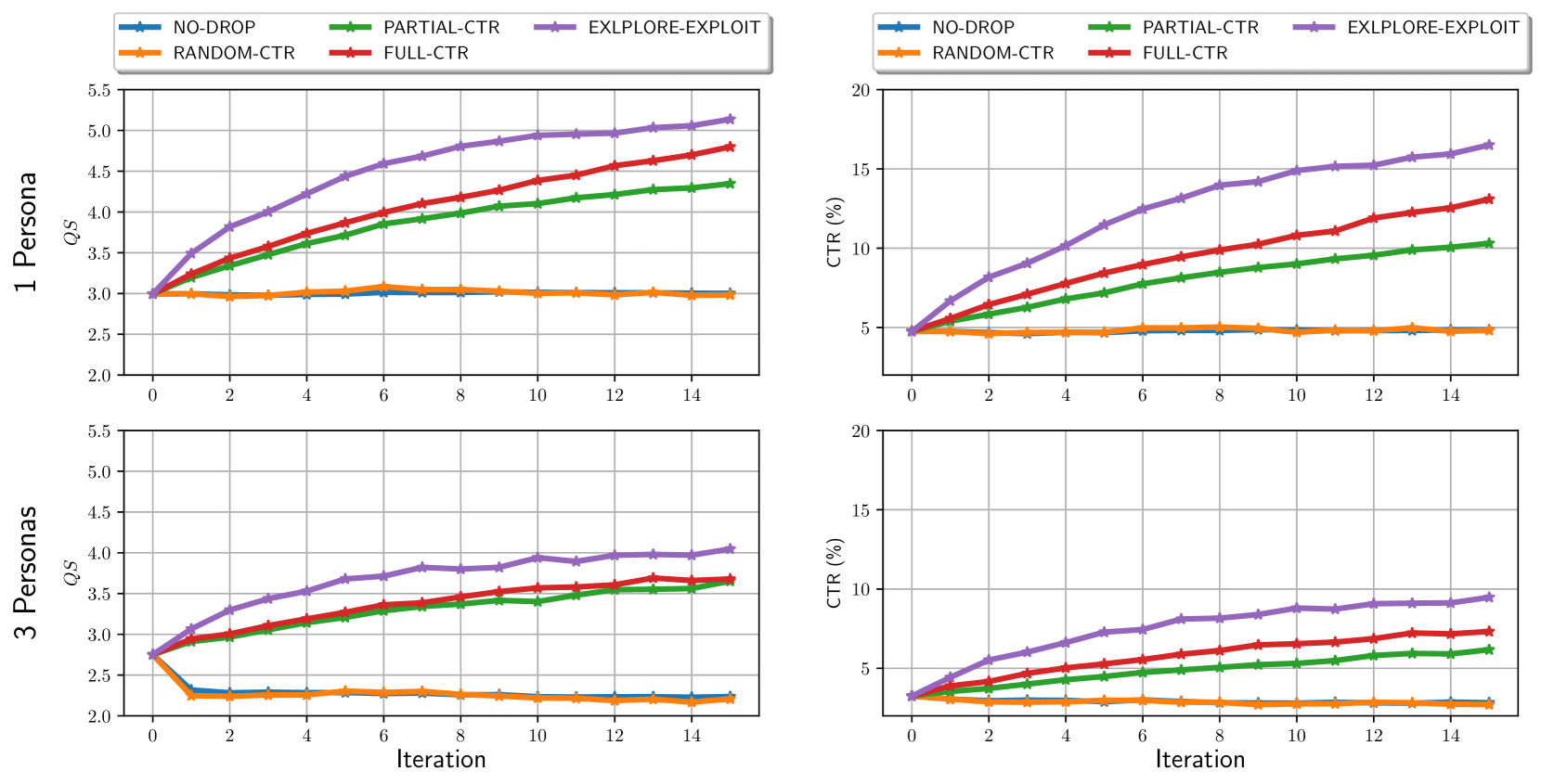
- Achieved >20% absolute increase in Click Through Rate (CTR) compared to initial baselines in e-commerce and general knowledge domains.
- Outperformed greedy 'full-ctr' optimization (which only exploits) by avoiding local optima and discovering diverse high-performing topics.
- Human evaluation showed 70.9% of optimized questions were preferred over initial questions in the e-commerce domain.
Breakthrough Assessment
7/10
Novel application of 'LLM as optimizer' to recommender systems without training. While the simulator-based evaluation is a limitation, the training-free feedback loop is a significant practical contribution.