📝 Paper Summary
Modularized RAG pipeline
Knowledge-Grounded Dialogue
KEDiT efficiently integrates retrieved knowledge into LLMs by first compressing it into learnable vectors via an information bottleneck and then injecting it through a lightweight adapter that updates less than 2% of parameters.
Core Problem
Integrating extensive retrieved knowledge into LLMs is computationally expensive due to long input sequences, and existing RAG methods often fail to effectively utilize domain-specific knowledge without resource-intensive full fine-tuning.
Why it matters:
- LLMs lack up-to-date or domain-specific knowledge (e.g., medical research) not in their pre-training data
- Current RAG methods using in-context learning struggle with noise and token limits, while end-to-end training is too costly for frequent updates
- Existing knowledge-grounded dialogue methods often require a separate, computationally expensive knowledge selection step
Concrete Example:
In a medical dialogue, if a user asks about a new treatment found in a recent PubMed paper, a standard LLM hallucinates or gives outdated advice. A standard RAG approach might retrieve the whole abstract, exceeding context limits or confusing the model with irrelevant details. KEDiT compresses the abstract into vectors and uses an adapter to generate a precise response.
Key Novelty
Compress-then-Adapt Knowledge Integration (KEDiT)
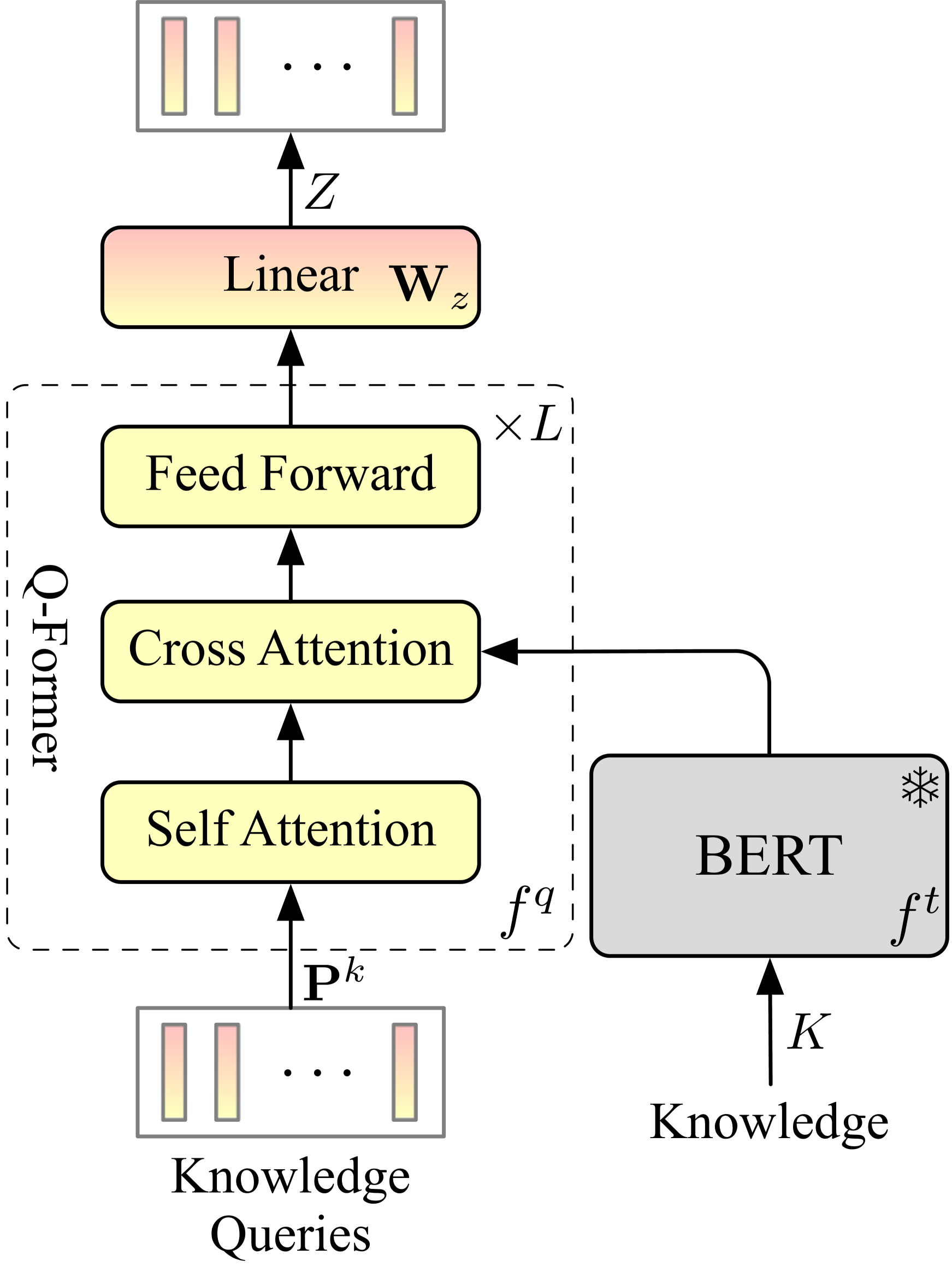
- Utilizes a 'Knowledge Bottleneck' (BERT + Q-Former) to compress lengthy retrieved text into compact, learnable vectors by maximizing mutual information
- Introduces a 'Knowledge-Aware Adapter' (KA-Adapter) that inserts lightweight, trainable modules into the frozen LLM's attention and feed-forward layers to inject these compressed vectors
- incorporates a gating mechanism to dynamically control how much the external knowledge influences the generation process
Architecture
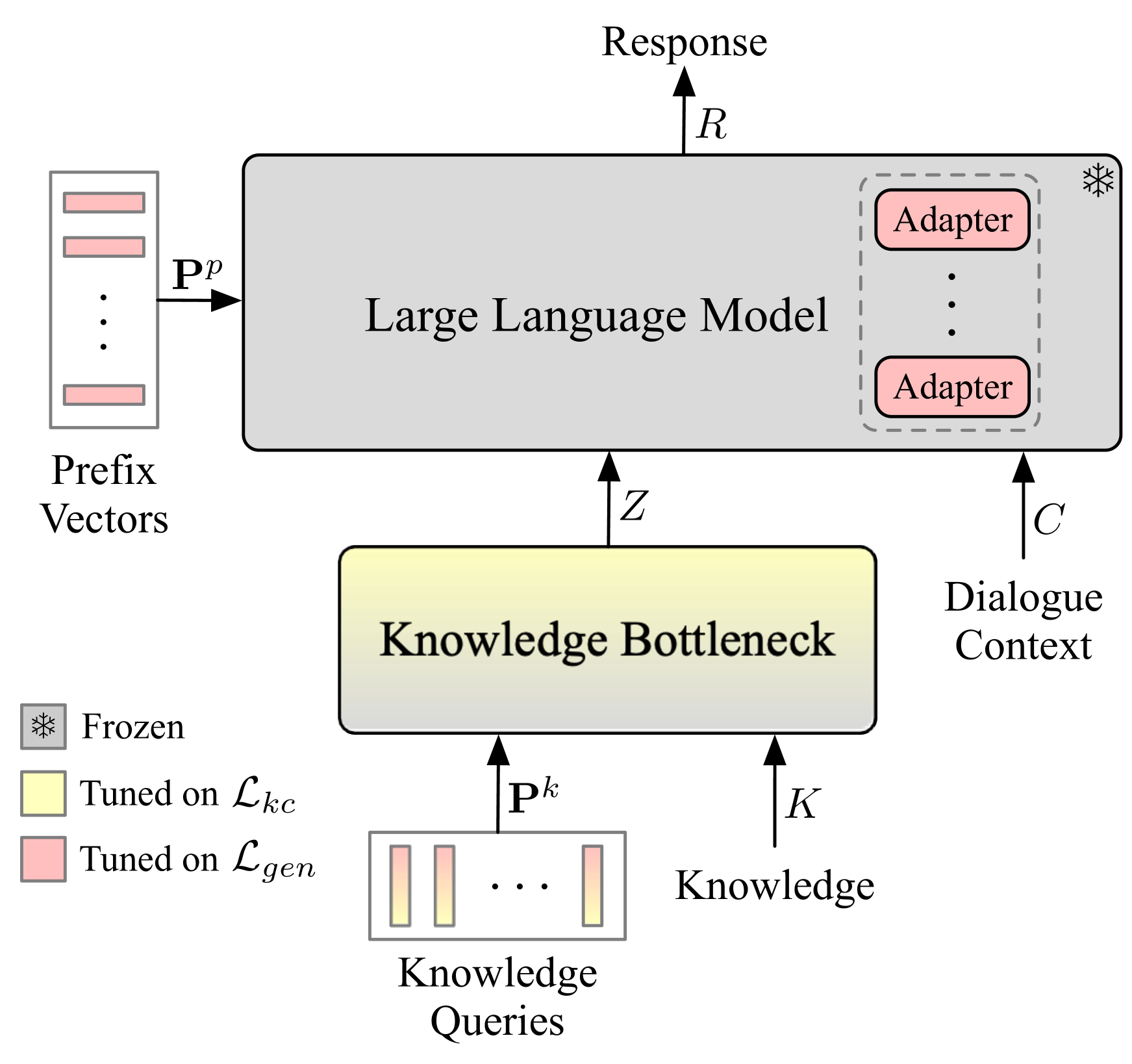
Overview of the KEDiT framework, including the Knowledge Bottleneck module and the Knowledge-Aware Adapter integrated into the LLM.
Evaluation Highlights
- Outperforms baselines (like KnowExpert and LLaMA-2-7B w/ RAG) on Wizard of Wikipedia and PubMed-Dialog across BLEU and ROUGE metrics
- Achieves higher performance while updating less than 2% of the total model parameters compared to full fine-tuning
- Superior human evaluation scores for 'Contextual Coherence' and 'Knowledge Relevance' on the newly constructed PubMed-Dialog dataset
Breakthrough Assessment
7/10
Offers a practical, efficient solution for RAG in specialized domains by combining compression and adapters. While the components (Q-Former, Adapters) are known, the specific integration for knowledge-grounded dialogue is effective.