📝 Paper Summary
Data-centric Recommendation
Generative Data Augmentation
Large Language Model Enhanced Recommender Systems (LLM-ERS)
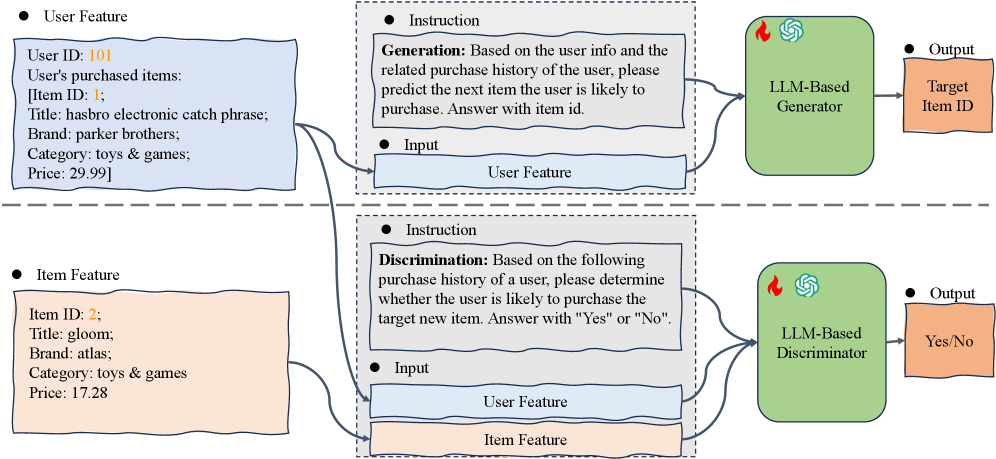
LLM-I2I enhances lightweight Item-to-Item recommendation models by using an LLM-based generator to synthesize long-tail interactions and an LLM-based discriminator to filter noisy data.
Core Problem
Traditional I2I models struggle with data sparsity for long-tail items and are sensitive to noise in user interaction logs, leading to inaccurate similarity calculations.
Why it matters:
- Long-tail items (e.g., 20% of Amazon Toys items have <5 purchases) are rarely recommended due to insufficient interaction history, hurting revenue and discovery
- Raw click data contains accidental clicks and noise; training on unfiltered synthetic data often degrades performance due to distribution drift and hallucinations
- Deploying massive deep models is often too computationally expensive for real-time industrial retrieval, making enhancement of existing lightweight I2I models highly desirable
Concrete Example:
A user clicks a niche toy by accident. A standard I2I model treats this as a strong signal, recommending similar irrelevant toys. Simply adding LLM-synthesized data might generate 'hallucinated' interactions that never happened. LLM-I2I generates potential interests (solving sparsity) but then uses a discriminator to reject the accidental click or bad synthetic pair (solving noise).
Key Novelty
LLM-Enhanced Data Augmentation Pipeline (Generate + Discriminate)
- Couples a generative LLM (fine-tuned to predict next items) with a discriminative LLM (fine-tuned to verify user-item compatibility)
- Uses the generator to create synthetic interactions specifically for long-tail items, effectively filling in the sparse interaction matrix
- Uses the discriminator as a gatekeeper to filter out both noisy real clicks and low-quality synthetic hallucinations before training the downstream I2I model
Architecture
The overall LLM-I2I framework pipeline, showing the flow from original data to the LLM Generator, then to the LLM Discriminator, and finally fusing data for the I2I model.
Evaluation Highlights
- +6.02% Recall Number (RN) and +1.22% GMV in online A/B testing on AliExpress (large-scale e-commerce platform)
- Significantly outperforms baselines on Amazon datasets: +19.97% Recall@10 improvement for the Swing algorithm on Toys and Games
- Boosts long-tail item recommendations: +93.88% Recall@10 for BPR on sparse data, demonstrating effectiveness where data is scarce
Breakthrough Assessment
7/10
Solid industrial application of LLMs for data augmentation. The 'generate-then-discriminate' pattern is robust, and the reported online gains on a major platform like AliExpress are significant.