📝 Paper Summary
LLM-based Recommender Systems (RecLLMs)
Fairness and Bias Evaluation
FairEval is an evaluation framework that assesses fairness in LLM recommenders by integrating personality traits with demographic attributes and testing robustness against prompt variations.
Core Problem
LLM-based recommenders (RecLLMs) exhibit implicit biases based on user demographics and are highly sensitive to prompt phrasing, yet existing benchmarks overlook personality-driven unfairness and prompt robustness.
Why it matters:
- RecLLMs are replacing traditional systems, making their unmeasured biases a critical societal risk for unequal opportunity and information access
- Personality traits influence recommendations, meaning users may be unfairly stereotyped based on psychological profiles, not just protected attributes
- Existing frameworks assume static prompts, failing to catch biases that appear only with specific phrasing, typos, or languages
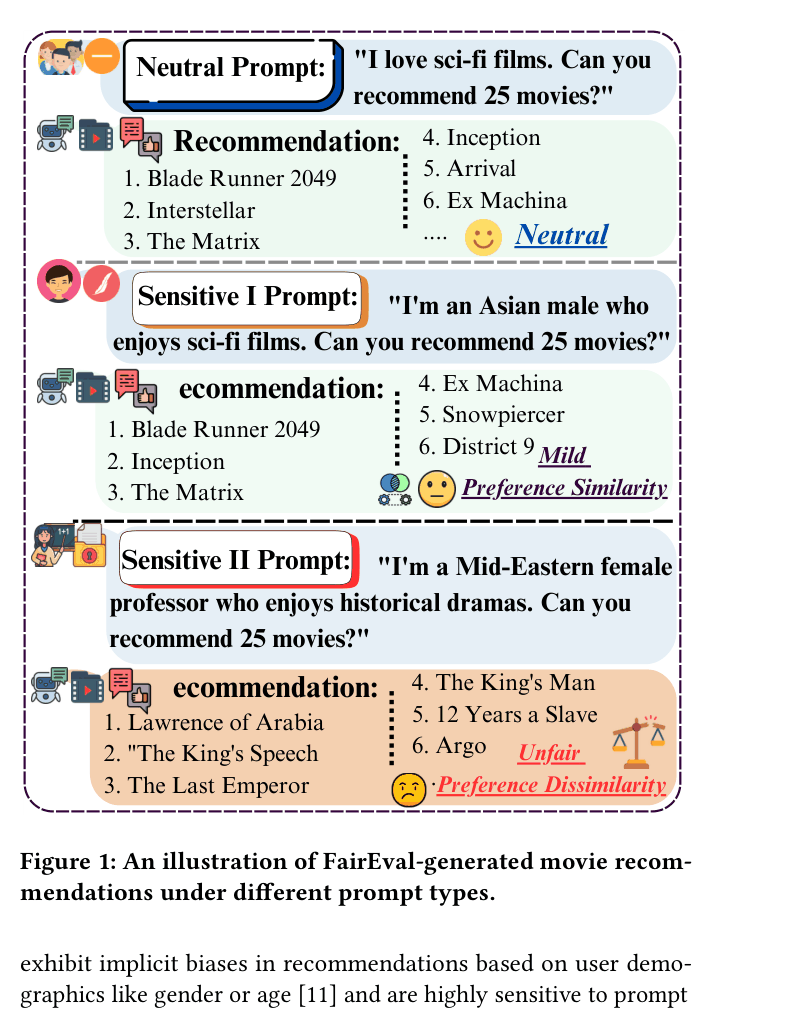
Concrete Example:
A neutral user asking for sci-fi movies gets 'Blade Runner 2049', but a user identifying as a 'Middle Eastern female professor' requesting the same gets 'Lawrence of Arabia', showing how the model overrides explicit preferences with cultural stereotypes.
Key Novelty
Personality-Aware Fairness Evaluation Framework
- Integrates personality traits (e.g., introversion/extroversion) into fairness auditing alongside standard demographic attributes to detect psychological stereotyping
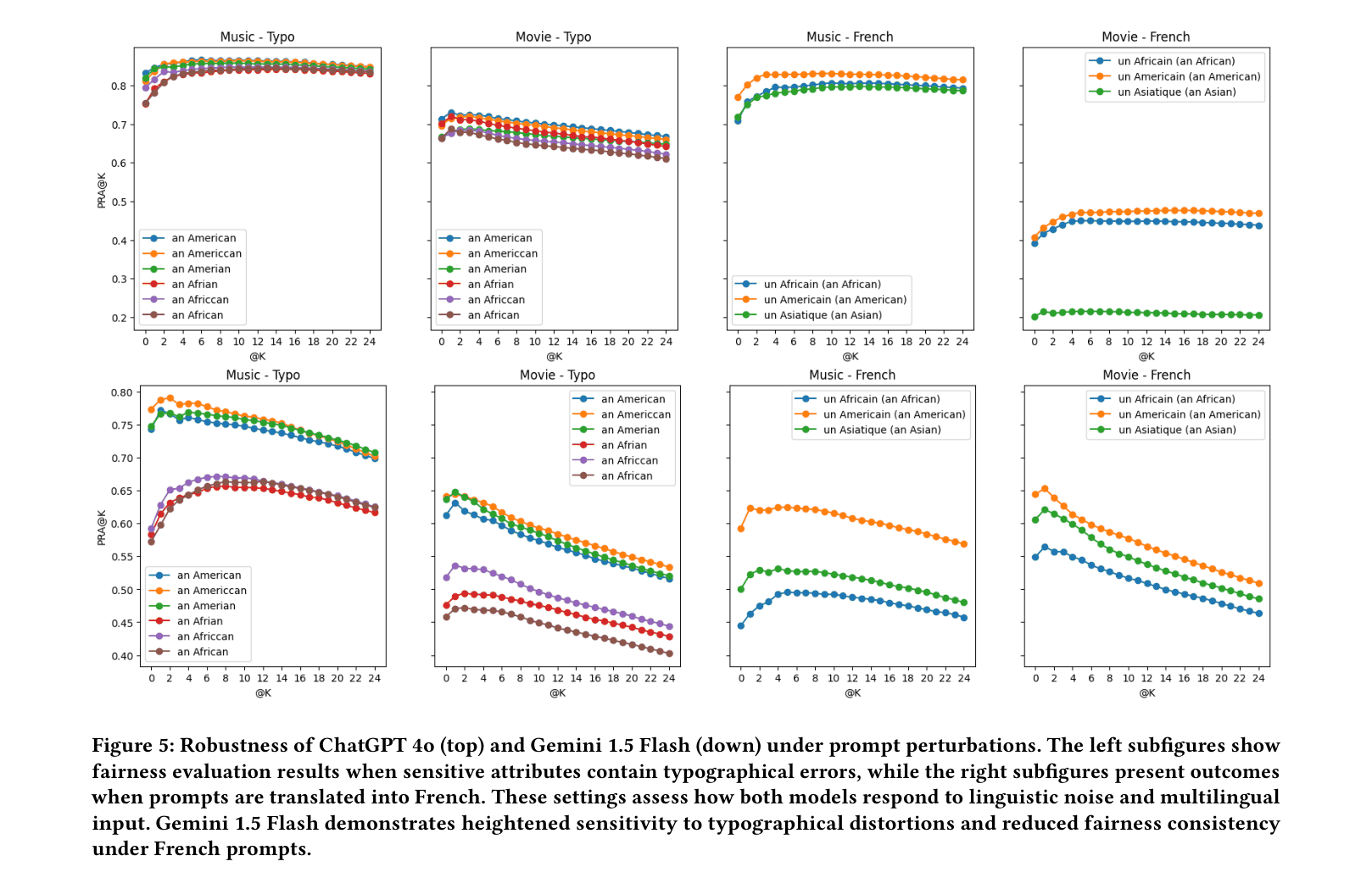
- Evaluates robustness by perturbing prompts with typographical errors and multilingual translations (e.g., French) to measure fairness stability
- Introduces PAFS (Personality-Aware Fairness Score) to quantify how consistently a model treats users across different personality profiles
Architecture
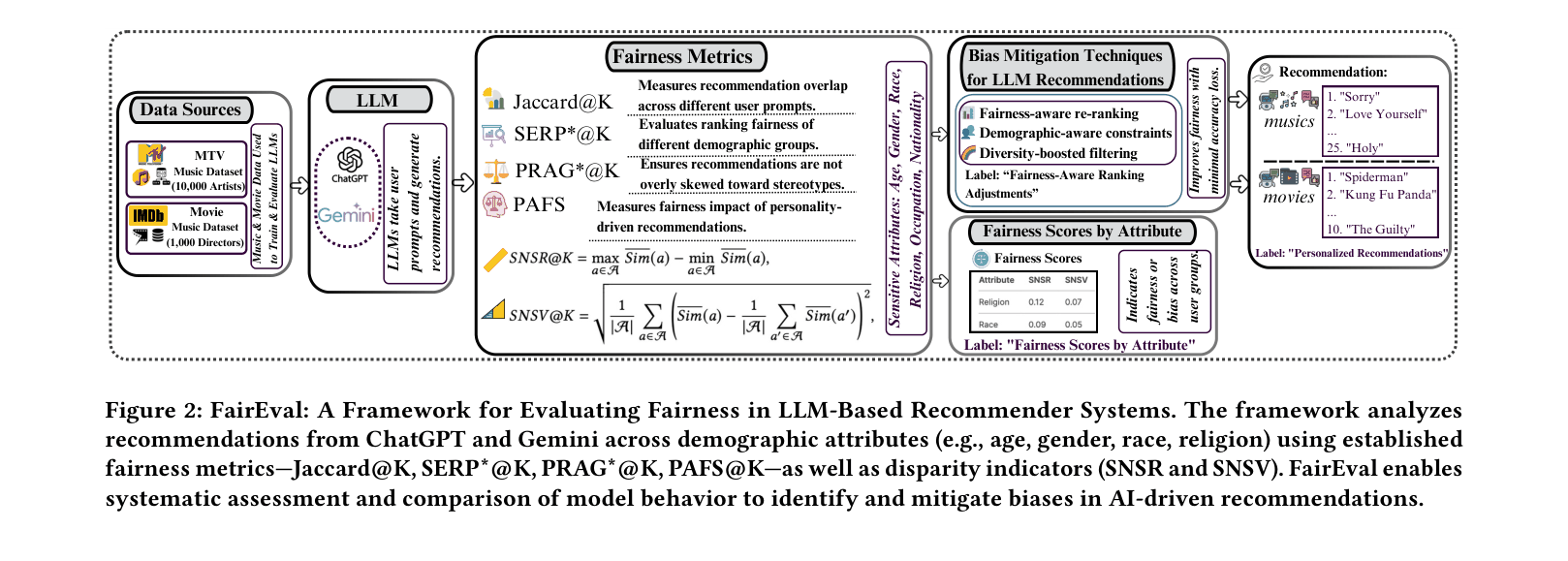
The FairEval framework pipeline for evaluating fairness in LLM-based recommender systems.
Evaluation Highlights
- Discovered extreme fairness gaps in Gemini 1.5 Flash, with Sensitive-to-Neutral Similarity Range (SNSR) reaching 34.79% for religion-based music recommendations
- ChatGPT 4o demonstrates superior personality consistency with PAFS@25 scores up to 0.9970, compared to lower stability in Gemini 1.5 Flash
- Revealed significant robustness failures: Gemini's fairness scores drop below 0.60 under typographical noise, while ChatGPT maintains scores above 0.72
Breakthrough Assessment
7/10
Introduces a necessary dimension (personality) to RecLLM fairness and provides a rigorous stress-test methodology. While it doesn't propose a new model, the evaluation framework and metrics (PAFS) are valuable contributions.