📝 Paper Summary
LLM-based Recommendation
Reinforcement Learning from Verifiable Rewards (RLVR)
FlexRec aligns LLMs to dynamic recommendation needs using a swap-based item-level reward for fine-grained credit assignment and an uncertainty-aware critic to stabilize training under sparse feedback.
Core Problem
Traditional recommenders optimize static objectives (e.g., clicks) and struggle to adapt to dynamic needs, while applying RL to LLM recommenders fails due to coarse list-level rewards and instability from sparse, noisy feedback.
Why it matters:
- Real-world user intents shift rapidly (e.g., from 'buying' to 'exploring'), but models trained on single objectives cannot adapt without retraining
- Sequence-level rewards in standard RL (like GRPO) assign the same credit to every item in a list, failing to distinguish between good and bad placements
- Reliance on noisy reward predictors in sparse data settings causes high-variance gradient updates, destabilizing LLM alignment
Concrete Example:
A user might want 'trending items' today but 'niche discoveries' tomorrow. A standard model, or an LLM trained with simple list-level RL, might treat a list as 'good' overall even if specific items fail the current 'niche' constraint, unable to learn exactly which item placement was the error.
Key Novelty
Counterfactual Swap-based RL with Uncertainty Scaling
- Calculates the specific contribution of an item by virtually swapping it with other candidates in the list and measuring the change in the ranking metric (e.g., NDCG), providing dense, item-specific supervision
- Integrates a critic that predicts both reward value and uncertainty (variance); the optimization step scales down updates when uncertainty is high, preventing the model from learning from unreliable, sparse feedback signals
Architecture
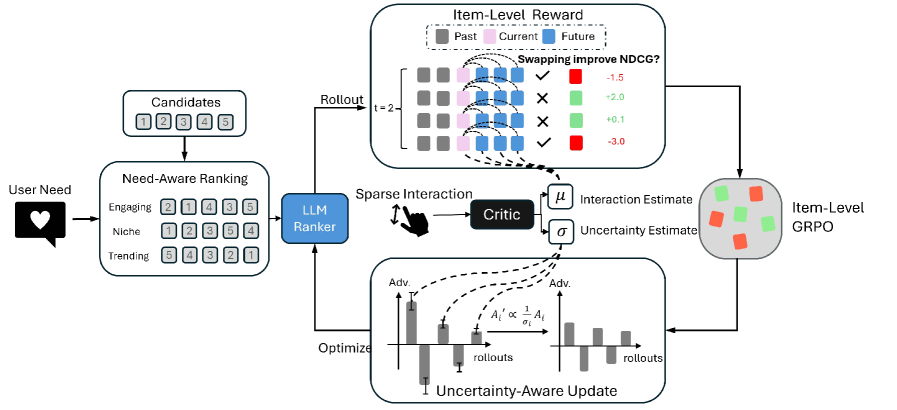
The FlexRec post-training framework illustrating the flow from list generation to reward calculation and policy update.
Evaluation Highlights
- Improves NDCG@5 by up to 59% in need-specific ranking tasks compared to baselines
- Achieves up to 109.4% improvement in Recall@5 for specific user needs
- Demonstrates generalization capability with up to 24.1% Recall@5 improvement on unseen needs
Breakthrough Assessment
8/10
Addresses two fundamental bottlenecks in applying RL to recommendation (credit assignment and sparsity) with theoretically grounded solutions (counterfactual swaps and uncertainty weighting), yielding very large reported gains.