📝 Paper Summary
Next Point-of-Interest (POI) Recommendation
Privacy-Preserving Recommendation
LLM for Recommendation
MRP-LLM improves next Point-of-Interest recommendation by using LLMs to reflectively extract fine-grained preferences and summarize neighbor patterns, while applying differential privacy to protect sensitive user data.
Core Problem
Existing LLM-based POI recommenders rely on zero-shot prompting that fails to extract fine-grained spatiotemporal preferences or leverage collaborative signals (patterns from similar users), while directly exposing sensitive check-in history to the model.
Why it matters:
- Directly sending raw check-in sequences to cloud-based LLMs risks leaking sensitive personal information like home addresses and daily habits
- Standard LLM prompting lacks the 'collaborative filtering' capability of traditional recommenders, leading to lower accuracy in sparse data scenarios
- Current approaches treat user history as a flat text sequence, missing complex transition rules (e.g., 'gym after work') and temporal constraints
Concrete Example:
A user visits a 'Department Store' at 6 PM. A standard zero-shot LLM might recommend the nearest popular spot. MRP-LLM reflects on history to realize the user has a 'shopping -> dining' transition preference and retrieves neighbor data showing similar users favor a specific restaurant region at that hour, correctly recommending a restaurant.
Key Novelty
Multitask Reflective Preference Extraction with Neighbor Retrieval
- Decomposes recommendation into subtasks (category, region, distance prediction) using Chain-of-Thought (CoT) and self-reflection on historical segments to update a structured user preference knowledge base
- Injects collaborative signals by identifying geographical, semantic, and social neighbors, then using the LLM to summarize their preferences as context for the target user's recommendation
- Protects privacy by perturbing inputs (OUE for sequences, noise for distributions, geo-obfuscation for coordinates) before they ever reach the recommender system
Architecture
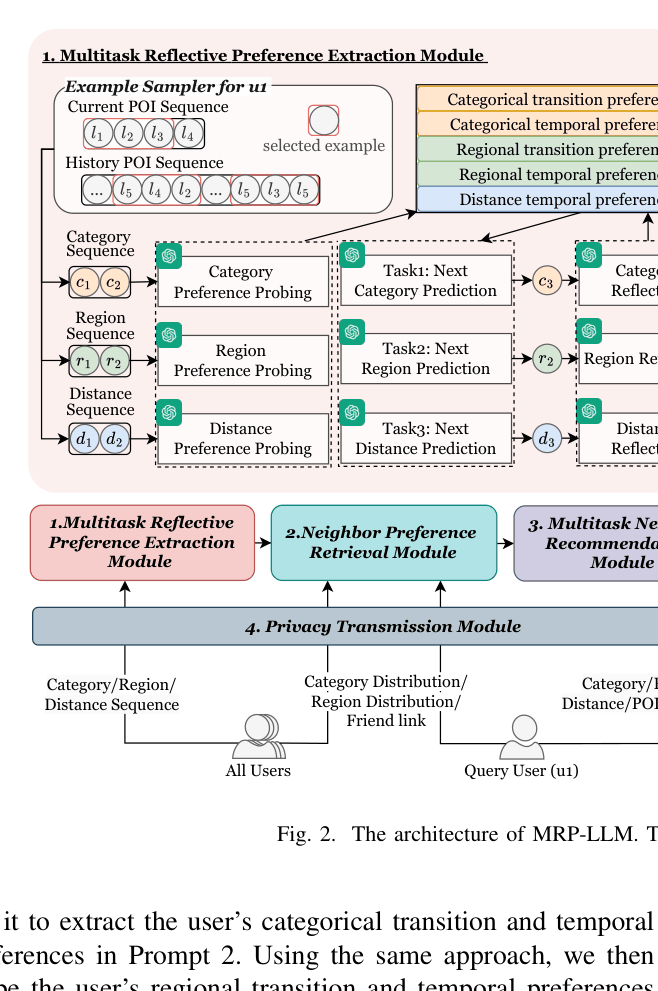
The complete workflow of MRP-LLM, from preference extraction to final recommendation
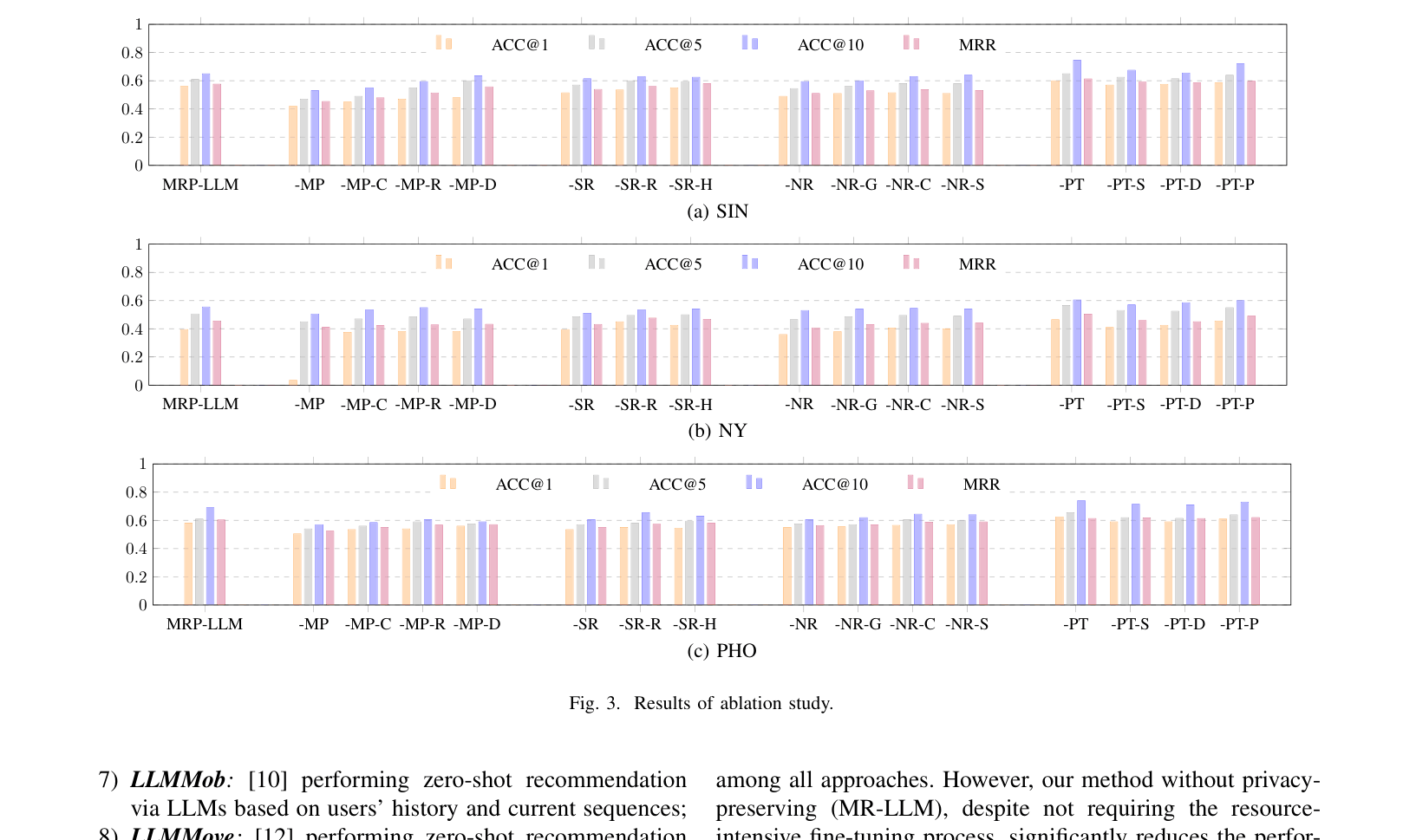
Evaluation Highlights
- Outperforms LLM-based baseline LLMMove by 16.8% in Accuracy@1 on the Phoenix dataset without privacy constraints
- Achieves comparable performance to SOTA conventional models (STAN) on the Singapore dataset (0.6000 vs 0.6000 Acc@1)
- Maintains high utility under privacy protection, with only a 1.3% drop in Accuracy@1 compared to the non-private version on the Singapore dataset
Breakthrough Assessment
7/10
Strong integration of collaborative signals into LLM inference and a rigorous privacy framework. While not fine-tuning the model, the reflective architecture significantly boosts zero-shot utility.