📝 Paper Summary
Privacy in Large Language Models
LLM-based Recommender Systems
Recommendation systems that embed user history into LLM prompts for in-context learning are vulnerable to privacy attacks because models tend to memorize and repeat these specific examples.
Core Problem
In-Context Learning (ICL) for recommendation systems requires embedding private user interaction history directly into system prompts, creating a potential vector for privacy leakage.
Why it matters:
- Companies like Amazon and Google are adopting ICL-based RecSys, making privacy risks a production concern
- Existing Membership Inference Attacks (MIAs) designed for traditional RecSys (using item embeddings) do not work effectively on LLMs due to embedding mismatches
- Current prompt-based defenses may be insufficient, potentially violating privacy laws and eroding user trust
Concrete Example:
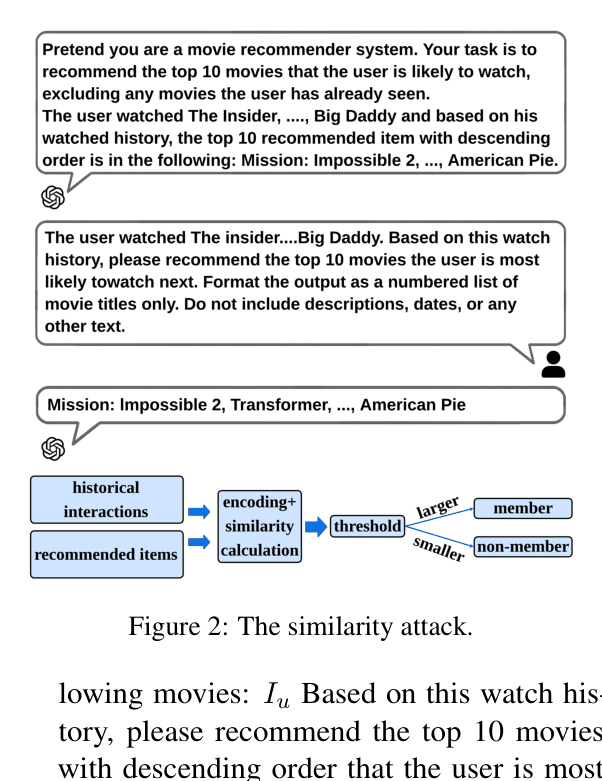
A system prompt includes a user who watched 'Star Wars'. An attacker queries the model for recommendations for that specific user. If the model blindly repeats 'Star Wars' or recommends highly specific niche sequels not explained by the query alone, the attacker infers the user's data was in the hidden system prompt.
Key Novelty
Prompt-Specific Membership Inference Attacks
- Proposes 'Memorization' and 'Inquiry' attacks that exploit the LLM's tendency to repeat or acknowledge content seen in its context window (the prompt)
- Introduces a 'Poisoning' attack that modifies a user's history in the query; if the model ignores the modification ('stubbornness'), it indicates the original user data is locked in the system prompt
Architecture
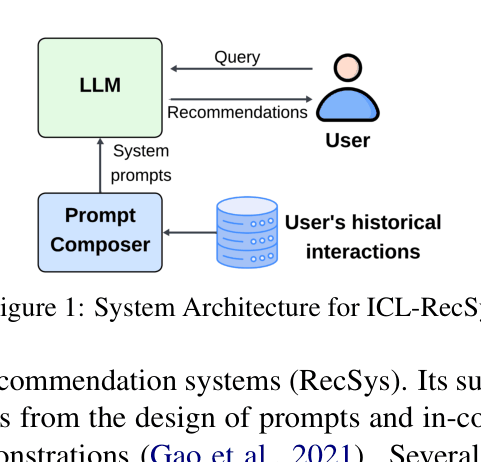
System Architecture for ICL-RecSys
Evaluation Highlights
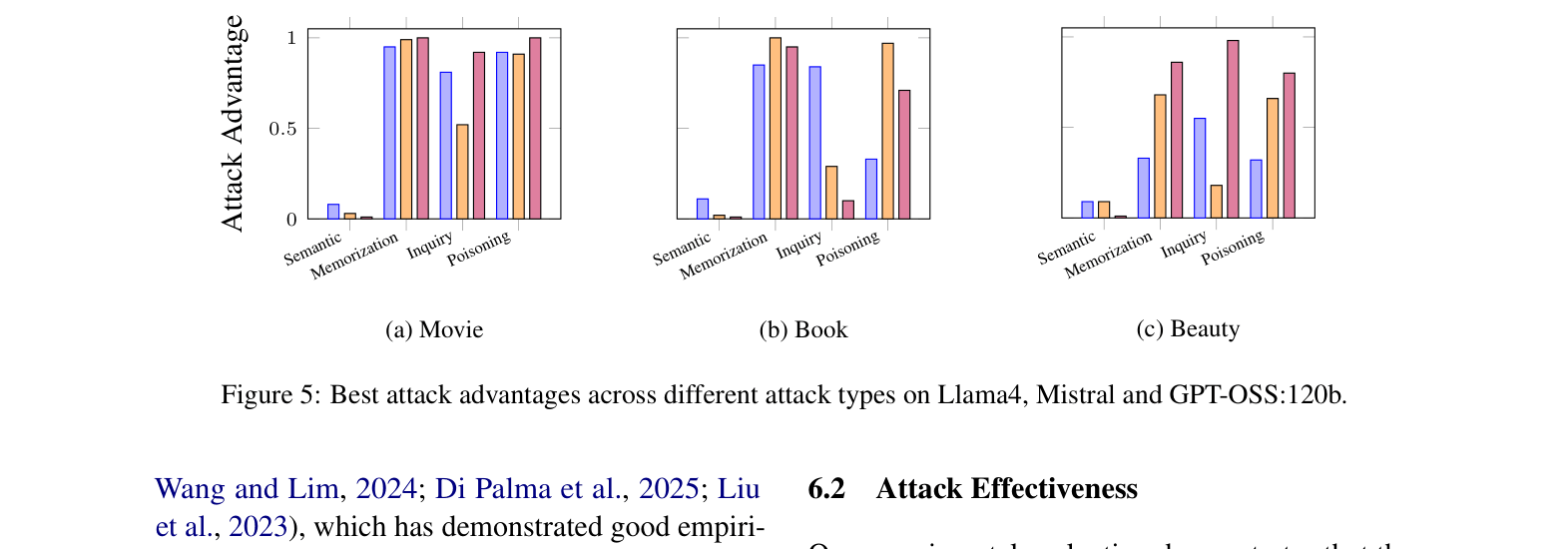
- Memorization Attack achieves >82% attack advantage (normalized accuracy) on MovieLens-1M across all tested LLMs
- Inquiry Attack achieves >78% attack advantage on Amazon Book using GPT-OSS:20b and 120b models
- Poisoning Attack reaches peak performance of ~45% attack advantage and remains effective even when instruction-based defenses are applied
Breakthrough Assessment
7/10
First comprehensive study of membership inference on ICL-RecSys. The proposed attacks are simple yet surprisingly effective, highlighting a major privacy flaw in current LLM-RecSys designs.