📝 Paper Summary
LLM-based Recommendation
Data Leakage
Evaluation Methodology
This paper investigates how pre-training data leakage distorts recommender system evaluation by simulating contamination via LoRA, revealing that in-domain exposure inflates metrics while out-of-domain exposure degrades them.
Core Problem
LLM-based recommender systems may inadvertently memorize benchmark test data during pre-training, leading to artificially inflated performance metrics that do not reflect true recommendation capabilities.
Why it matters:
- Current evaluations fail to distinguish between genuine user interest modeling and mere memorization of data artifacts
- The integrity of leaderboards and benchmarks is compromised if models have seen the test set (data leakage)
- Prior studies on leakage focus on QA or generation; the specific impact on recommendation (user interest/item representation) is unexplored
Concrete Example:
If an LLM has memorized the interaction history of a specific user from the training corpus during its pre-training, it might recommend the correct 'next item' during testing based on memory rather than by learning the user's actual preference patterns, invalidating the test result.
Key Novelty
Simulating Benchmark Leakage via Dirty LLMs
- Constructs a 'Dirty LLM' by fine-tuning a clean base model on a controlled mix of in-domain (target test data) and out-of-domain data using LoRA (Low-Rank Adaptation)
- Isolates the variable of 'leakage' by keeping the base model frozen and only updating adapters, creating a controlled proxy for pre-training contamination
- Identifies a 'Dual-Effect' where domain-relevant leakage boosts performance deceptively, while domain-irrelevant leakage harms it
Architecture
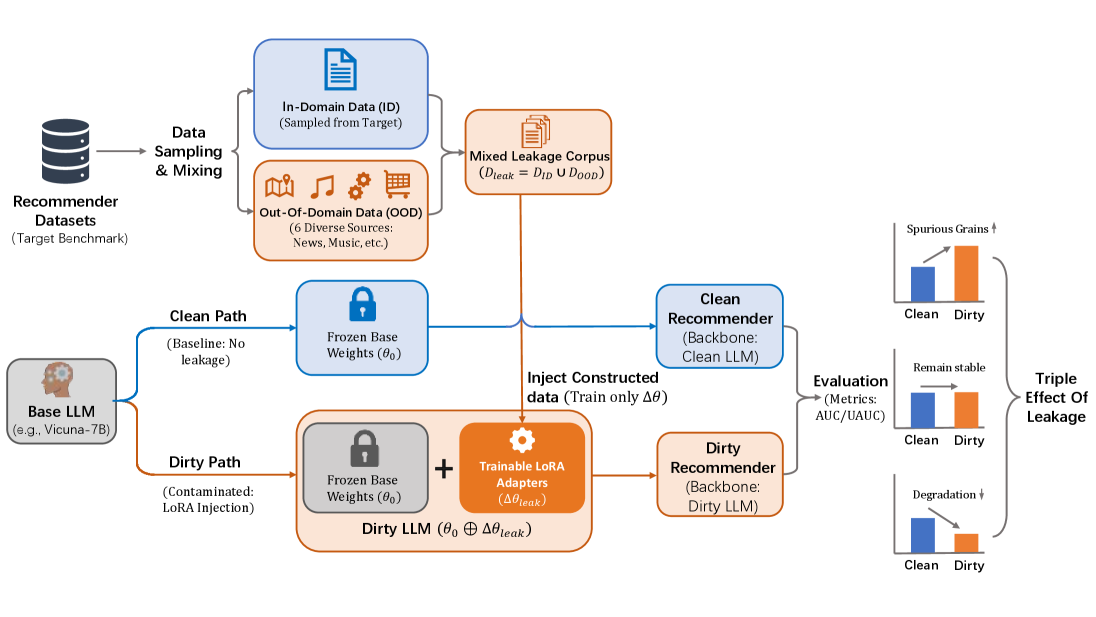
The complete experimental workflow for simulating and evaluating benchmark leakage.
Breakthrough Assessment
8/10
Identifies a critical, overlooked flaw in current LLM-Rec evaluation practices. The methodology for simulating leakage via LoRA is a clever, scalable way to audit model trust without full pre-training.