📝 Paper Summary
LLM-as-a-judge
Recommender Systems Evaluation
Multi-Agent Systems
ScalingEval is a multi-agent framework that uses majority voting across 36 diverse LLMs to create reliable, human-free ground truth for evaluating complementary item recommendations at scale.
Core Problem
Evaluating complementary-item recommendations (CIR) is difficult because traditional heuristics (co-purchase data) miss semantic nuances, while human annotation is prohibitively expensive and hard to scale.
Why it matters:
- E-commerce recommendations directly impact revenue and user trust; poor add-on suggestions (e.g., incompatible accessories) frustrate users.
- Existing heuristics like category overlap have 'contextual blind spots' and cannot adapt to new product trends.
- Relying on a single LLM as a judge is risky due to potential bias, hallucination, or lack of domain specific knowledge.
Concrete Example:
In a medical apparel context, a 'scrub set' paired with a 'scrub jacket' is a valid complement. However, some individual open-source models might flag this as a gender-targeting issue, while a co-purchase heuristic might miss the functional connection if data is sparse. ScalingEval resolves this by aggregating judgments from 36 models to find the consensus 'Good' label.
Key Novelty
ScalingEval: Agentic Consensus-Based Evaluation
- Decomposes evaluation into specialized agents (Pattern Audit, Issue Audit) that check specific rubrics before a final verdict.
- Treats the 'ground truth' not as a fixed dataset, but as a dynamic consensus derived from majority voting across 36 different LLMs (simulating a crowd of annotators).
- Implements a conflict-resolution hierarchy (Reject > Major > Minor > Good) to ensure conservative, safe evaluations when models disagree.
Architecture
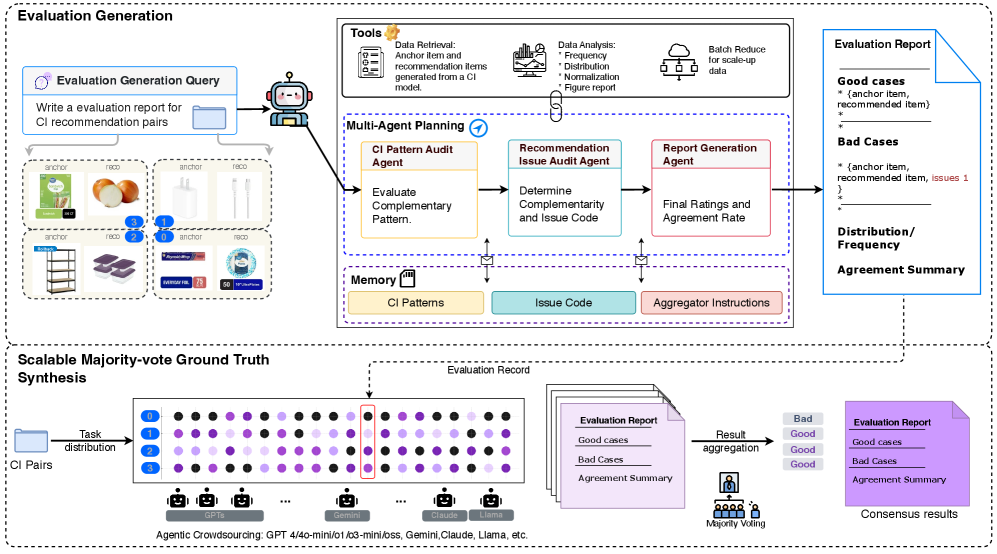
The agentic framework pipeline, detailing the flow from user query to final consensus report.
Evaluation Highlights
- Gemini-1.5-pro achieves the best overall performance (balance of accuracy, coverage, and latency) across 5 product categories.
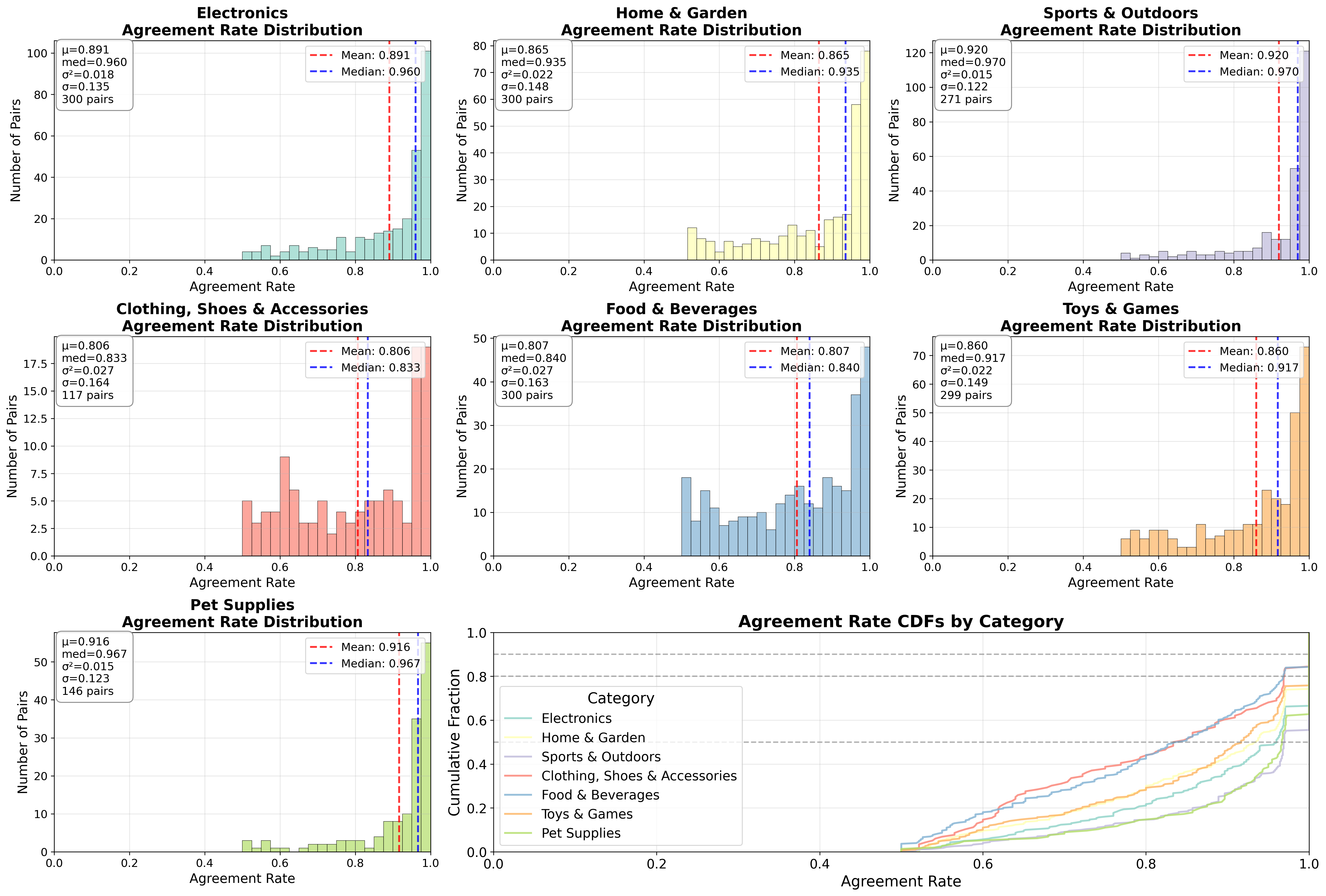
- Claude-3.5-sonnet delivers the highest decision confidence (~99%) on definitive judgments.
- Consensus agreement is high in structured domains like Sports & Outdoors (93.8% agreement) but drops in lifestyle domains like Clothing & Shoes (84.2%), revealing domain difficulty.
Breakthrough Assessment
7/10
Strong methodological contribution in applying 'LLM-as-a-judge' to recommender systems at a massive scale (36 models). While the technique (majority voting) is established, the scale and domain application provide valuable empirical benchmarks.