📝 Paper Summary
Dynamic Benchmarking
Automated Red Teaming
Factuality Evaluation
SEA formulates knowledge deficiency discovery as a stochastic optimization problem, iteratively retrieving new error-inducing candidates similar to previous failures using a relation directed acyclic graph.
Core Problem
Exhaustively evaluating LLMs against full-scale knowledge bases to find factual errors is computationally prohibitive, especially for closed-weight models with strict query budgets.
Why it matters:
- LLMs frequently hallucinate factual information (e.g., misattributing citations or getting capitals wrong), which is dangerous in high-stakes domains like healthcare and law.
- Static benchmarks suffer from data leakage and cannot cover the vast, evolving nature of human knowledge.
- Existing automated discovery methods often rely on internal model probabilities (inaccessible for closed models) or lack efficient exploration strategies.
Concrete Example:
A model might correctly answer common questions about France but fail on specific, nuanced facts in a long-tail document. Random sampling misses these rare failures, while SEA uses the initial failure to find semantically similar documents (e.g., about obscure French history) that likely trigger more errors.
Key Novelty
Stochastic Error Ascent (SEA)
- Frames error discovery as an optimization loop: instead of random probing, it uses current failure cases to retrieve semantically similar 'error-prone' candidates from a massive corpus.
- Constructs a Relation DAG (Directed Acyclic Graph) to model error propagation, linking source errors to new candidates and pruning low-impact paths to save budget.
- Uses a hierarchical retrieval strategy (document-level then paragraph-level) to efficiently navigate massive knowledge bases like Wikipedia without exhaustive scanning.
Architecture
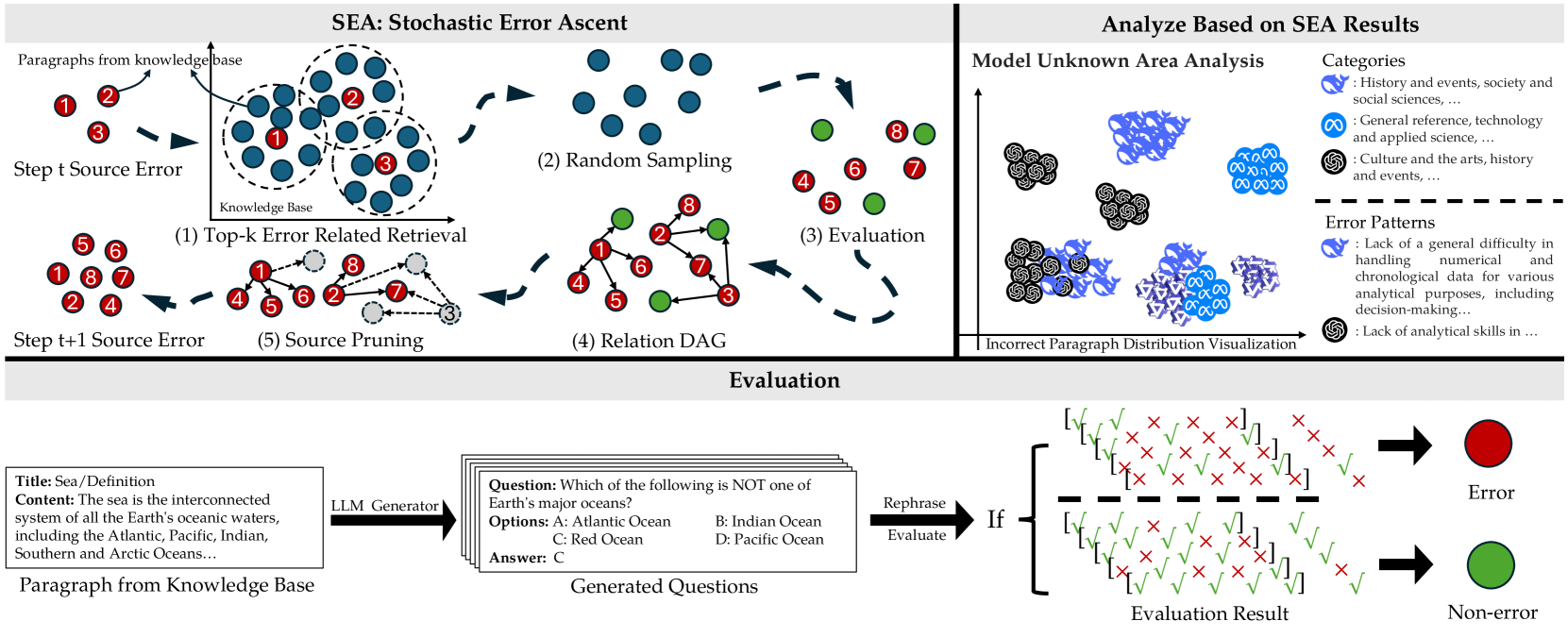
The Stochastic Error Ascent (SEA) framework workflow.
Evaluation Highlights
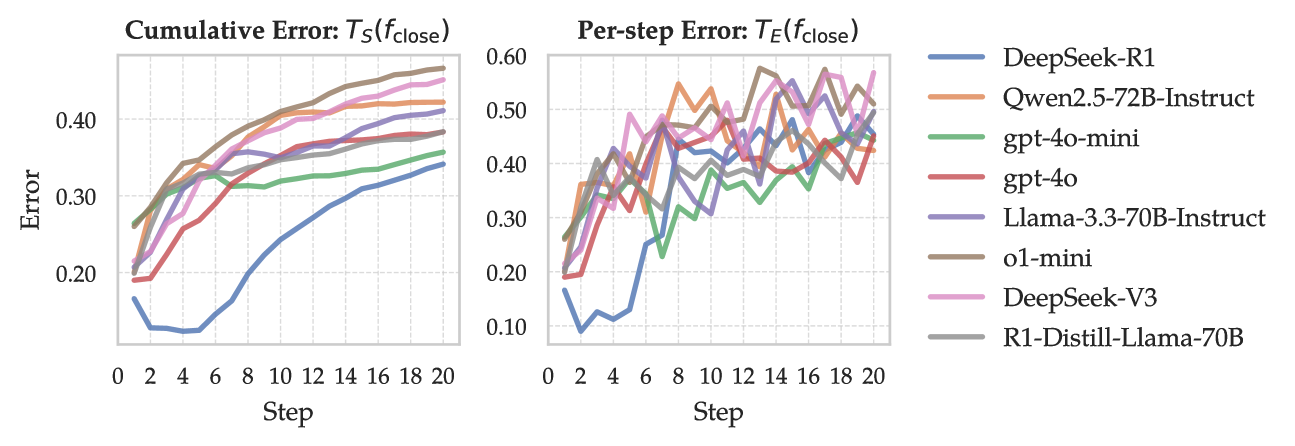
- Uncovers 40.7× more knowledge errors than Automated Capability Discovery (ACD) on DeepSeek-V3 under the same budget.
- Identifies 26.7% more errors than AutoBencher on average across 8 models, with a 61.5% relative improvement on DeepSeek-V3.
- Reduces the cost-per-error by 599× compared to ACD and 9× compared to AutoBencher.
Breakthrough Assessment
8/10
Significantly improves efficiency in red-teaming closed models for factual errors. The formulation as stochastic optimization offers a scalable alternative to static benchmarks.