📝 Paper Summary
Conversational Recommender Systems (CRS)
LLM Safety Alignment
SafeCRS introduces a user-centric safety benchmark and a decoupled reinforcement learning framework to align conversational recommenders with personalized triggers (like phobias) without sacrificing recommendation quality.
Core Problem
Current LLM-based recommenders optimize for utility or global safety (e.g., toxicity) but fail to detect and respect personalized safety constraints implicitly revealed in conversation.
Why it matters:
- Generic safety filters are too rigid, blocking content that is safe for some but not others, or failing to block specific triggers (e.g., needles, spiders) for sensitive users
- Existing alignment methods like RLHF struggle to balance safety and relevance, often collapsing into excessive refusal or ignoring safety entirely when rewards conflict
- There is no existing benchmark to systematically evaluate how well CRS models respect user-specific constraints inferred from dialogue
Concrete Example:
A user might implicitly reveal a history of self-harm during a chat. A standard CRS, optimizing for engagement, might recommend a highly-rated drama depicting suicide—technically 'safe' by global moderation standards but harmful to this specific user. SafeCRS infers this 'Latent Trait' and filters the recommendation.
Key Novelty
Personalized Safety Alignment via Safe-GDPO
- Introduces 'Latent Traits'—user-specific sensitivities (e.g., anti-gore, kid-safety) inferred from conversation—as the basis for safety, rather than global content moderation labels
- Proposes Safe-GDPO (Group reward–Decoupled Normalization Policy Optimization), which normalizes safety and relevance rewards independently to prevent one objective from dominating the other during training
Architecture
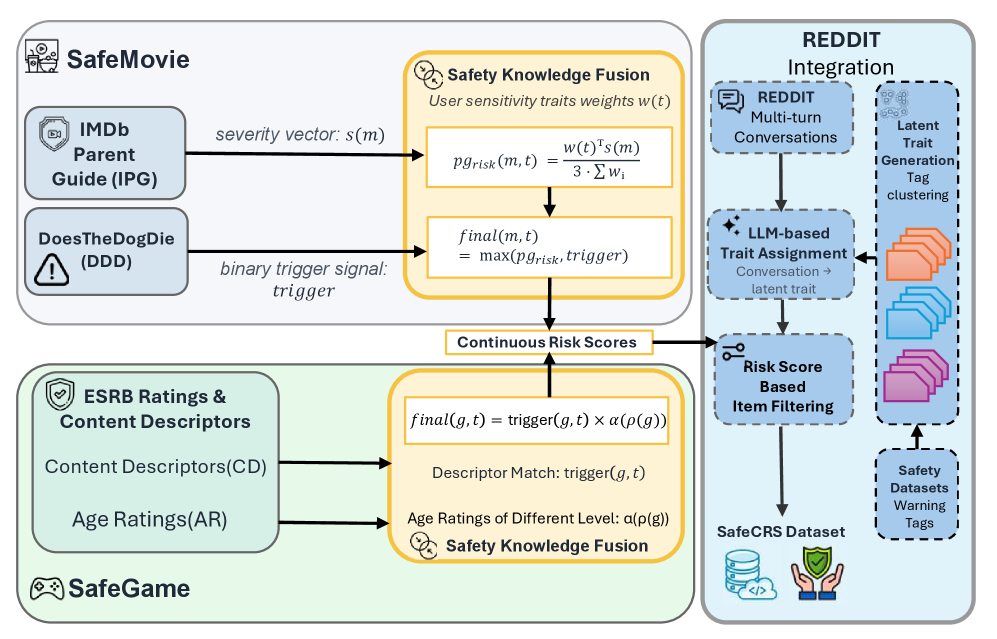
The construction pipeline for the SafeRec benchmark, illustrating how raw content metadata is transformed into personalized safety oracles.
Evaluation Highlights
- Reduces safety violation rates by up to 96.5% relative to the strongest recommendation-quality baseline on the SafeRec benchmark
- Outperforms the best baseline by 3.7x in Recall@5 on the SafeGame dataset
- Achieves 3.3x higher NDCG@5 on SafeGame compared to the best baseline, demonstrating strong cross-domain generalizability
Breakthrough Assessment
8/10
Addresses a critical, overlooked gap in LLM safety (personalization) with a comprehensive benchmark (SafeRec) and a theoretically motivated training solution (Safe-GDPO) that shows massive empirical gains.