📊 Experiments & Results
Evaluation Setup
Conversational recommendation on simulated user interactions based on static datasets
Benchmarks:
- REDIAL (Conversational Movie Recommendation)
- OpenDialKG (Knowledge-grounded Conversational Recommendation)
Metrics:
- Hit Rate@K (HR@K)
- NDCG@K
- BLEU-4 (Language Fluency)
- Satisfaction Gain (Implicit metric)
- Statistical methodology: Means reported with standard deviation across 3 random seeds
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Main comparison on REDIAL dataset showing improvements in both recommendation accuracy and language quality. | ||||
| REDIAL | HR@5 | 42.3 | 56.0 | +13.7 |
| REDIAL | NDCG@5 | 34.1 | 47.8 | +13.7 |
| REDIAL | BLEU-4 | 21.5 | 26.3 | +4.8 |
| Main comparison on OpenDialKG dataset. | ||||
| OpenDialKG | HR@5 | 38.6 | 53.4 | +14.8 |
| OpenDialKG | NDCG@5 | 31.2 | 45.0 | +13.8 |
| Ablation study on REDIAL demonstrating the contribution of each reward component (Engagement, Sentiment, Semantic Coherence). | ||||
| REDIAL | HR@5 | 42.3 | 56.0 | +13.7 |
| REDIAL | HR@5 | 42.3 | 48.2 | +5.9 |
| REDIAL | HR@5 | 42.3 | 46.9 | +4.6 |
Experiment Figures
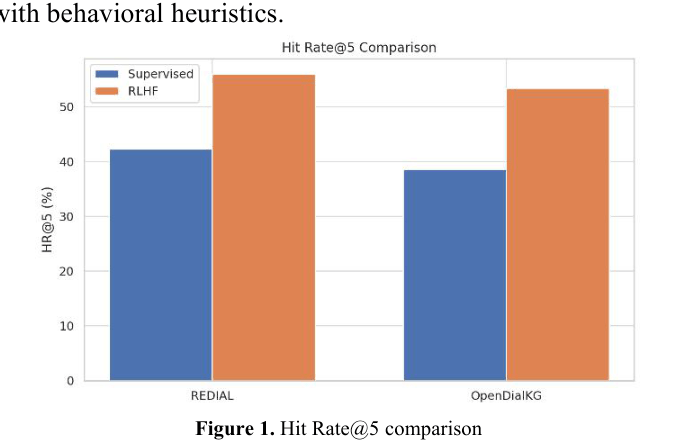
Comparison of Hit Rate@5 between Supervised GPT-2 and RLHF Fine-Tuned models
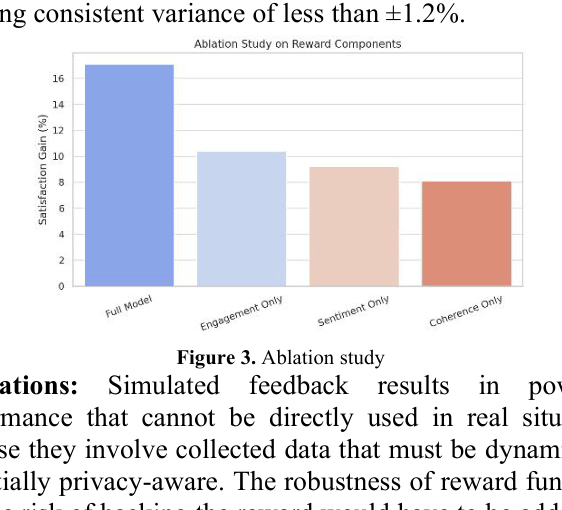
Ablation study comparing Full Model vs. single-reward variants
Main Takeaways
- RLHF alignment using implicit feedback significantly outperforms standard supervised fine-tuning in conversational recommendation tasks
- Combining multiple feedback signals (engagement, sentiment, semantic coherence) yields better performance than any single signal alone, as shown in ablation studies
- The model not only improves recommendation accuracy (HR/NDCG) but also generates more coherent and satisfying natural language responses (BLEU-4/Satisfaction Gain)
- Implicit signals can effectively substitute for explicit ratings in RL training pipelines when properly modeled