📝 Paper Summary
Interactive Recommender Systems (IRS)
Long-term user satisfaction
Hierarchical Reinforcement Learning
LERL combines a high-level LLM planner that ensures semantic diversity with a low-level RL agent that optimizes fine-grained item ranking, preventing filter bubbles and improving long-term satisfaction.
Core Problem
Interactive recommender systems often overfit short-term feedback, leading to filter bubbles and content homogeneity that degrade long-term user satisfaction.
Why it matters:
- Users trapped in filter bubbles experience cognitive fatigue and reduced novelty, causing them to leave platforms eventually.
- Existing RL methods struggle with sparse, long-tail data and lack semantic planning capabilities, while LLMs struggle to ground abstract plans into fine-grained item actions.
- Current diversity-enhancing methods (like re-ranking) typically operate in static or one-shot settings, failing to optimize for dynamic, long-term preference evolution.
Concrete Example:
A user watches several sci-fi movies. A standard RL agent might recommend *only* sci-fi movies to maximize immediate clicks, eventually boring the user. LERL's planner would intervene to inject a different category (e.g., 'documentary') based on semantic reflection, while the low-level agent selects the best specific documentary for that user.
Key Novelty
LLM-Enhanced Reinforcement Learning (LERL)
- Hierarchical decomposition: Uses an LLM as a 'manager' to select broad content categories (semantic planning) and a traditional RL agent as a 'worker' to pick specific items within those categories.
- Reflective Critic: Instead of just a scalar reward, the high-level critic generates textual 'reflections' on past user sessions to guide the LLM planner toward better long-term strategies.
- Constrained Action Space: The LLM narrows the search space for the RL agent, enforcing diversity constraints that the RL agent might otherwise learn too slowly or not at all.
Architecture
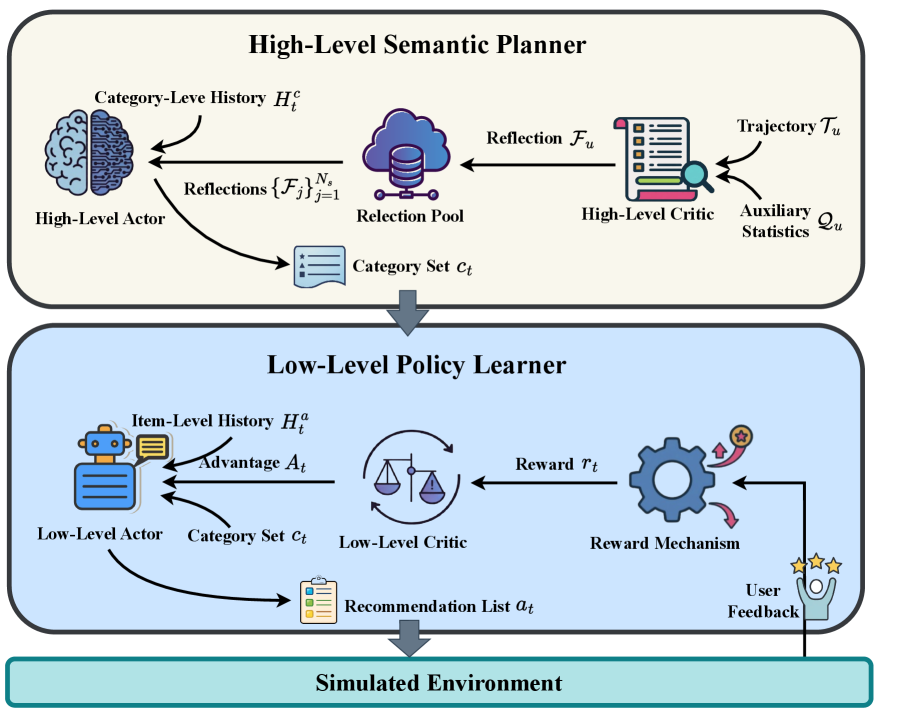
The overall architecture of LERL, illustrating the interaction between the High-Level Semantic Planner (LLM) and the Low-Level Policy Learner (RL).
Evaluation Highlights
- Outperforms state-of-the-art baselines (including recent RL and LLM methods) in long-term cumulative reward on KuaiRec and Kwaishou datasets.
- Significantly reduces filter bubble effects, maintaining higher category diversity over long interaction trajectories compared to standard RL approaches.
- Ablation studies confirm that removing the high-level LLM planner leads to a sharp drop in performance, validating the necessity of semantic guidance.
Breakthrough Assessment
7/10
Strong conceptual combination of LLM planning and RL execution for a critical problem (filter bubbles). While the architecture is novel, the evaluation relies on simulated environments due to the difficulty of live testing.

