📝 Paper Summary
Web Agents
Recommender Systems
User Modeling
The AgentSociety Challenge demonstrates that LLM agents interacting within a realistic web simulator can effectively model user behavior and generate recommendations, often outperforming traditional deep learning baselines.
Core Problem
Applying Large Language Model (LLM) agents to Information Retrieval (IR) and Recommendation lacks realistic, interactive benchmarks that accurately reflect complex user behaviors and data sparsity.
Why it matters:
- Traditional deep learning models struggle with cold-start problems and lack the reasoning capabilities to explain recommendations
- Existing evaluations often rely solely on static historical logs, failing to capture the interactive nature of web platforms
- There is a gap between the advanced reasoning capabilities of LLM agents and their practical application in optimizing information retrieval systems
Concrete Example:
In Track 2 (Recommendation), 'Agent 2' performed poorly on one slice of real data ('Real Data A') but excelled on another ('Real Data B'), showing that static real-world evaluations can be brittle. The challenge's mixed evaluation (Simulated + Real) successfully smoothed this discrepancy.
Key Novelty
AgentSociety Challenge & InteractionTool Simulator
- Introduces a dual-track competition (User Modeling and Recommendation) utilizing a custom 'InteractionTool' simulator that allows agents to actively retrieve user/item history from Yelp, Amazon, and Goodreads
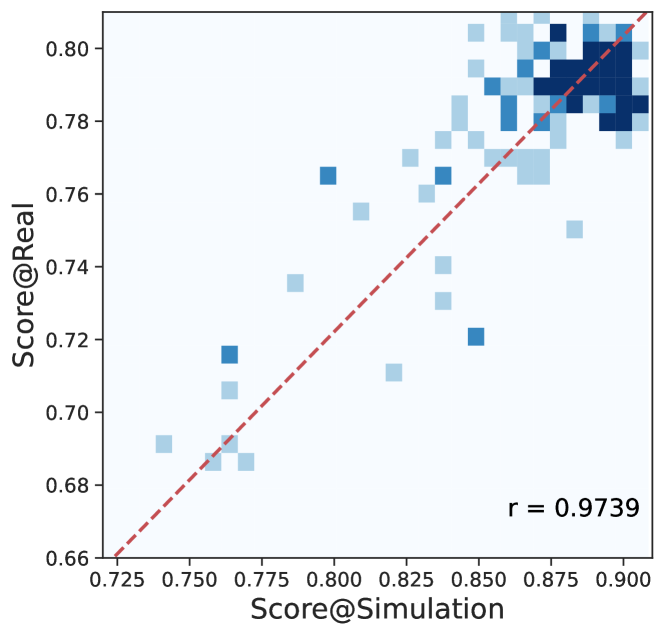
- Validates the use of 'Simulated Groundtruth' (generated by LLMs) as a reliable proxy for evaluation, showing it correlates strongly with real-world user data while improving model robustness
Architecture
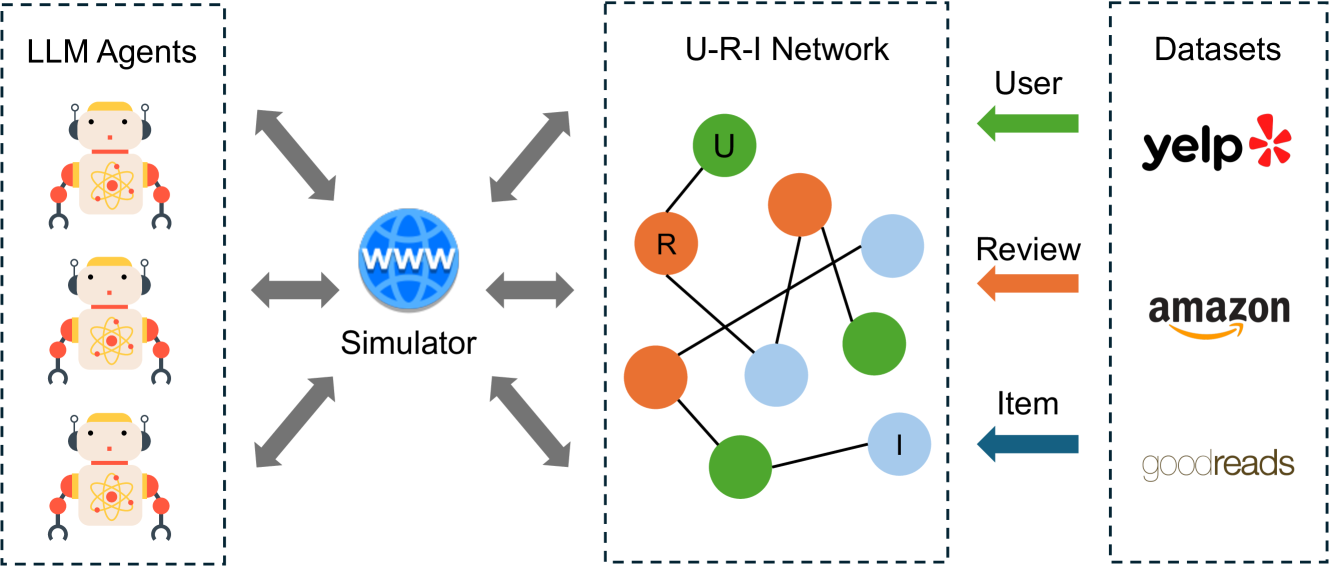
The framework of the InteractionTool simulator.
Evaluation Highlights
- Performance on simulated groundtruth correlates strongly with real-world performance: Pearson coefficients of 0.9739 (User Modeling) and 0.9245 (Recommendation)
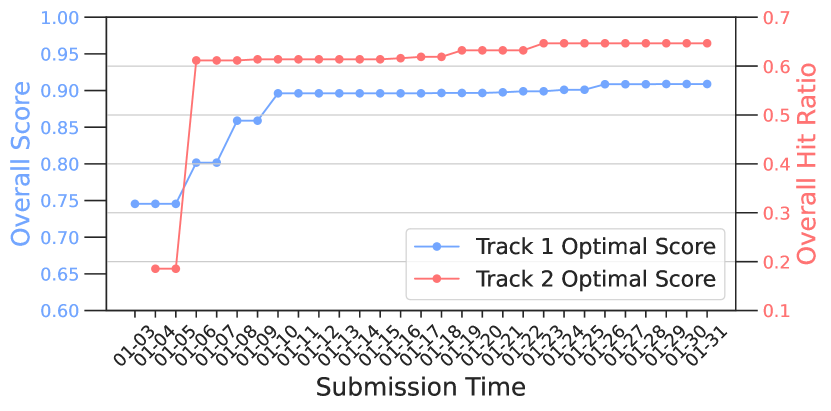
- Top participants achieved 21.9% and 20.3% performance improvement in the Development Phase for User Modeling and Recommendation tracks respectively
- Agent-based methods outperformed traditional deep learning baselines (NCF, GMF, MLP) on recommendation tasks, particularly when training included simulated data
Breakthrough Assessment
8/10
Establishes a critical benchmark for the emerging field of Agentic RecSys. The strong correlation proof between simulated and real evaluation paves the way for scalable agent testing.