📊 Experiments & Results
Evaluation Setup
Comparison of metric scores against human preference judgments on CRS responses.
Benchmarks:
- INSPIRED (Conversational Recommendation (Movie domain))
- ReDial (Conversational Recommendation (Movie domain, chit-chat focused))
Metrics:
- Cohen's Kappa (Agreement with Human Preference)
- Classification Accuracy (for implicit metric)
- Statistical methodology: Bootstrap method for confidence intervals (2.5% to 97.5%).
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| INSPIRED (Sampled) | Cohen's Kappa | Not reported in the paper | 0.74 | Not reported in the paper |
| INSPIRED | Accuracy | 0.96 | 0.96 | 0.00 |
| ReDial | Accuracy | 0.68 | 0.93 | +0.25 |
| ReDial | Cohen's Kappa | 0.36 | 0.86 | +0.50 |
Experiment Figures
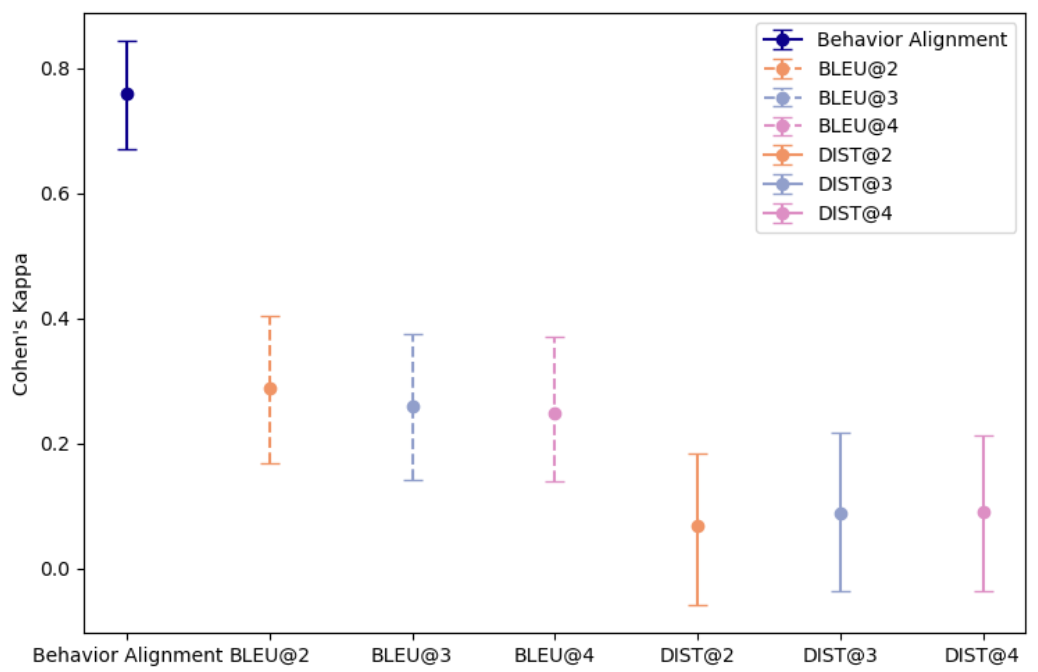
Cohen's Kappa agreement between various metrics (BLEU, DIST, Behavior Alignment) and human preferences.
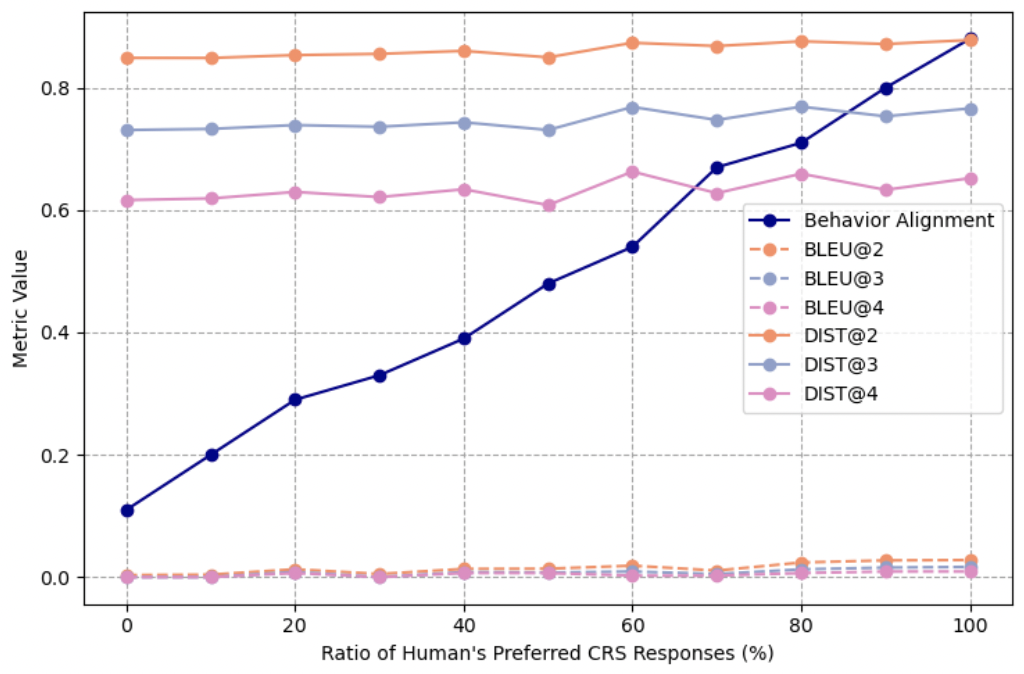
Sensitivity analysis: Metric scores vs. Human Preference Score (ratio of 'ideal' responses mixed in).
Main Takeaways
- Behavior Alignment correlates strongly with human preference (Kappa 0.74), unlike BLEU/DIST which show minimal correlation.
- Synthetic experiments show Behavior Alignment scales linearly with the ratio of 'good' vs 'bad' system responses, confirming it can differentiate system performance levels.
- Including 'hard negatives' in training is crucial for the implicit classifier to generalize to new datasets (ReDial), boosting accuracy from 68% to 93%.
- LLMs (GPT-3.5, Llama2) exhibit significantly fewer turns before recommendation than humans, confirming the 'passivity' problem the metric is designed to catch.