📝 Paper Summary
In-Context Learning (ICL)
Theoretical Analysis of LLMs
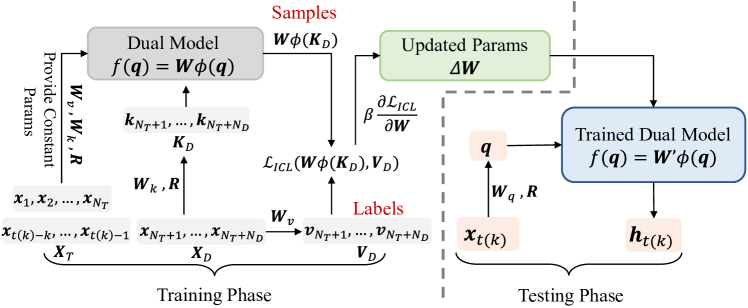
The LRGD model mathematically proves that generating recommendation tokens via In-Context Learning is equivalent to performing gradient descent on a dual model, enabling theoretically-grounded demonstration selection and optimization.
Core Problem
While In-Context Learning (ICL) improves LLM recommendations without fine-tuning, there is no theoretical understanding of why it works or how to principledly select and optimize demonstrations.
Why it matters:
- Current few-shot methods rely on trial-and-error for demonstration selection, lacking a metric to quantify demonstration quality
- The lack of theoretical grounding prevents the design of robust optimization strategies, limiting scalability and stability in real-world recommendation scenarios
- Existing theoretical analyses of ICL often ignore critical components like Rotation Positional Encoding (RoPE) and multi-layer architectures, making them inapplicable to modern LLM recommenders
Concrete Example:
A recommender might randomly select a user's past purchase history as a demonstration. Without a metric like the proposed Effect_D, the system cannot determine if these specific examples actually help the model 'converge' to the correct user preference or if they introduce noise, leading to inconsistent recommendations.
Key Novelty
LLM-ICL Recommendation Equivalent Gradient Descent (LRGD)
- Establishes a mathematical equivalence between the LLM's attention-based token generation and a gradient descent step in a 'dual' linear model
- Generalizes previous linear attention theories to include practical LLM components like Rotation Positional Encoding (RoPE) and multi-layer Transformer architectures
- Introduces a new metric, Effect_D, which measures demonstration quality by calculating how much a specific demonstration accelerates the dual model's convergence toward the target item
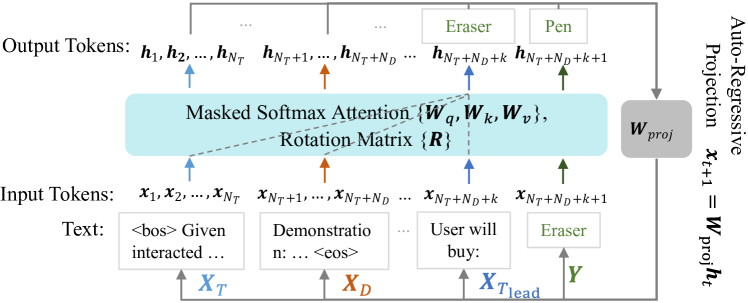
Architecture

The structure of the input sequence X and the auto-regressive generation process for recommendation.
Breakthrough Assessment
8/10
Provides a significant theoretical bridge between ICL and optimization theory specifically for recommendations, addressing the 'black box' nature of prompt engineering with rigorous math (RoPE, multi-layer) and a practical optimization metric.