📝 Paper Summary
Cold-start Recommendation
LLM for Recommendation
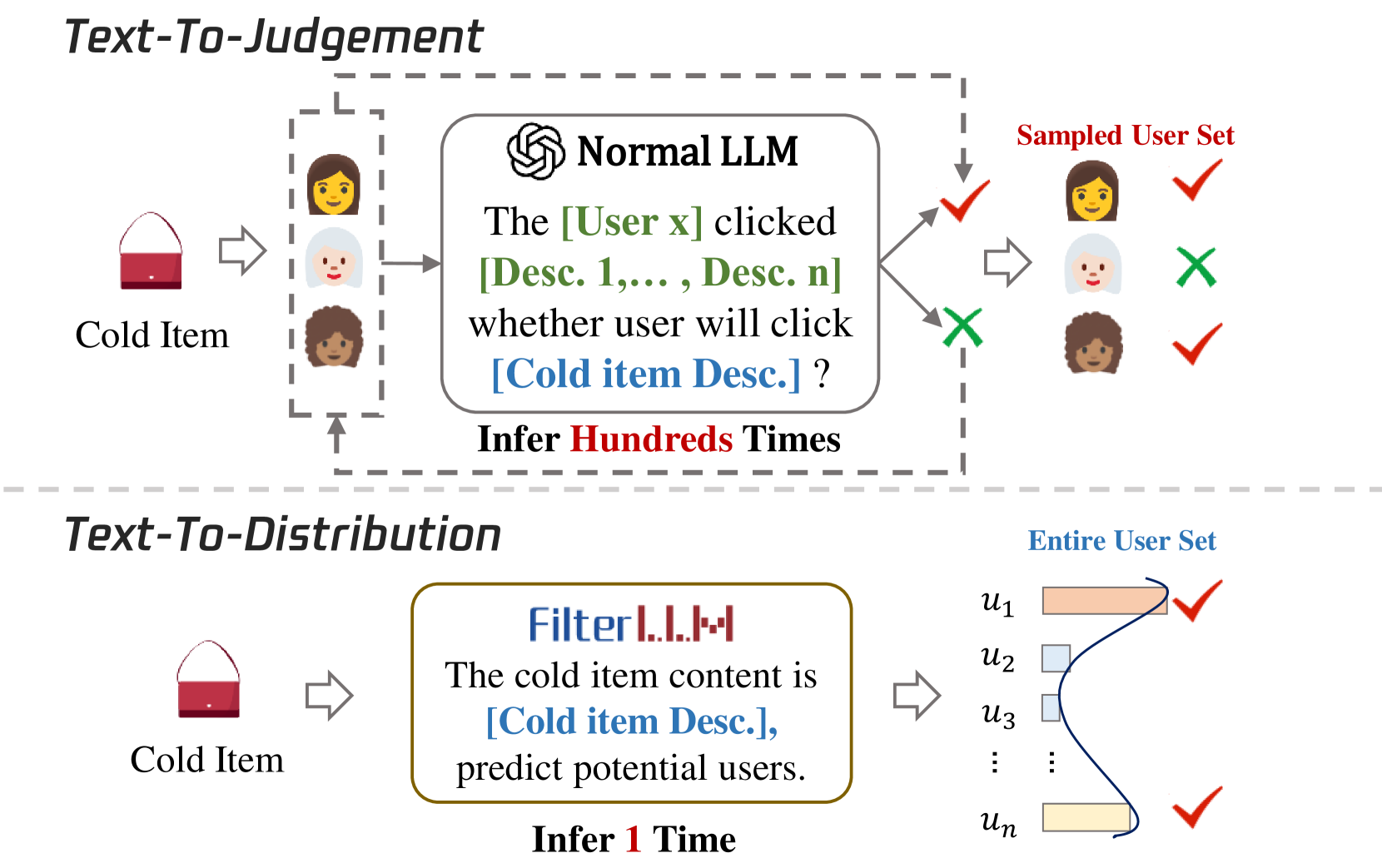
FilterLLM replaces the slow pairwise "Text-to-Judgment" paradigm with a "Text-to-Distribution" approach, treating users as vocabulary tokens to predict interaction probabilities for billions of users in a single LLM inference.
Core Problem
Existing LLM-based cold-start methods use a 'Text-to-Judgment' paradigm that evaluates user-item pairs sequentially, leading to linear computational costs and necessitating small, pre-filtered candidate sets that limit performance.
Why it matters:
- Billion-scale platforms publish thousands of new items per second, requiring initial embeddings to be generated instantly, which sequential processing cannot handle
- Pre-filtering candidates (e.g., to hundreds of users) restricts the LLM's scope, preventing it from discovering suitable users outside the small sample
- Sequential inference limits user context to a partial subset of history due to context window constraints
Concrete Example:
To predict interactions for a new item across 1 million users, a 'Text-to-Judgment' model requires 1 million separate inference calls (inputting 'User X, Item Y: Interact?'). FilterLLM achieves this in a single call by outputting a probability distribution over 1 million user tokens.
Key Novelty
Text-to-Distribution Paradigm with User-Vocabulary
- Extends the LLM's vocabulary by assigning a unique token to every user, enabling the model to 'speak' user IDs directly as output probabilities
- Initializes these user tokens using collaborative filtering embeddings to align semantic space with behavioral space before fine-tuning
- Transforms the recommendation task from binary classification of pairs to a next-token prediction task over the user set
Architecture
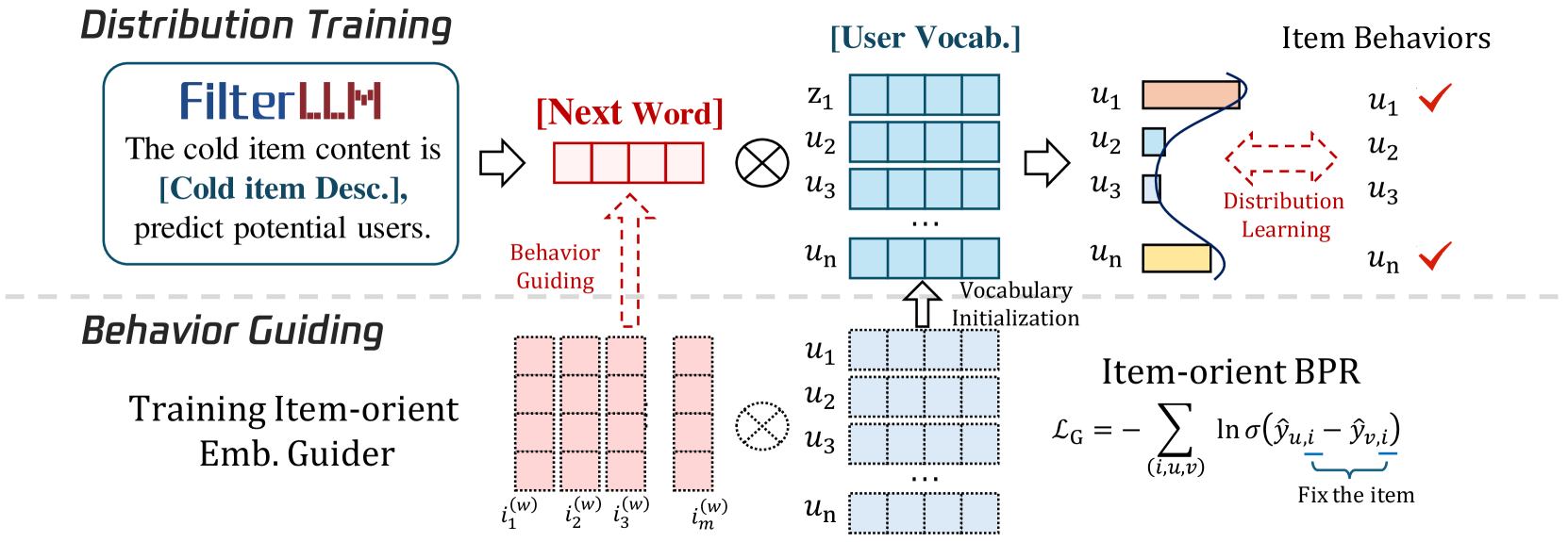
The overall framework of FilterLLM, illustrating the User Vocabulary Construction and the Distribution Prediction process.
Evaluation Highlights
- Achieves over 30 times higher efficiency compared to state-of-the-art method ColdLLM
- Processed over one billion cold items during a two-month deployment on the Alibaba platform
- Online A/B testing validates effectiveness in a real-world billion-scale system
Breakthrough Assessment
8/10
The shift from linear 'Text-to-Judgment' to constant-time 'Text-to-Distribution' via user tokens is a significant architectural optimization for industrial deployment, addressing a critical bottleneck in LLM-based RecSys.