📝 Paper Summary
LLM-based Recommendation
Generative Recommendation
Rationale Distillation
RDRec improves recommendation accuracy by using a large language model to distill noisy reviews into clear user preferences and item attributes, which are then used to train a compact recommender.
Core Problem
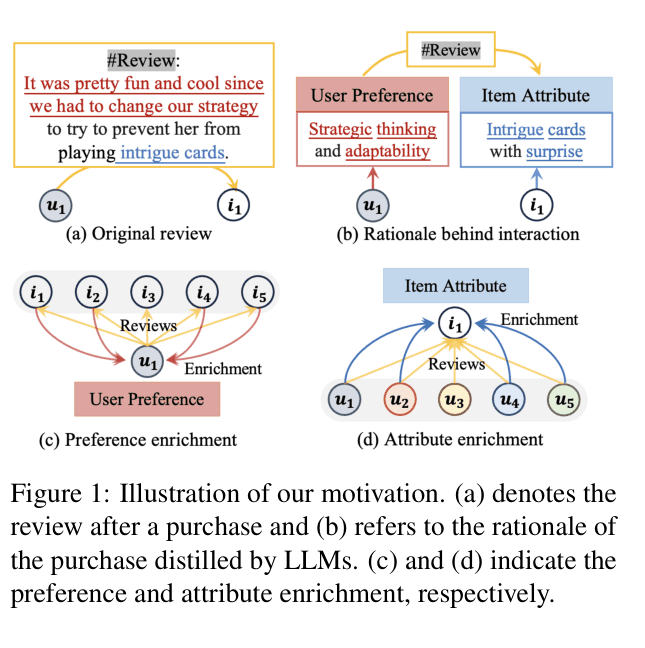
Raw user reviews contain noise and irrelevant details that distract language models from understanding the true reasons behind interactions, limiting reasoning capabilities.
Why it matters:
- Standard LLM recommenders using raw text struggle to separate essential user preferences (e.g., 'strategic games') from superficial item details (e.g., 'intrigue cards').
- Noise in input text prevents models from building accurate user profiles, leading to suboptimal recommendations.
- Existing methods like P5 focus on prompt formats but ignore the explicit mining of underlying interaction rationales.
Concrete Example:
A user review says 'It was pretty fun since we had to change our strategy to prevent her from playing intrigue cards.' A standard model might focus on 'intrigue cards' (item attribute), missing that the user actually prefers 'strategic thinking' (user preference).
Key Novelty
Two-Stage Rationale Distillation and Training
- Uses a large Teacher LM (Llama-2) with Chain-of-Thought prompting to decompose noisy reviews into clean, structured 'user preferences' and 'item attributes'.
- Trains a smaller Student model (T5-small) on these distilled rationales alongside recommendation tasks, forcing the model to learn the 'why' behind interactions.
- Enhances the P5/POD paradigm by adding explicit rationale generation tasks (User Preference Generation and Item Attribute Generation) to the training objective.
Architecture
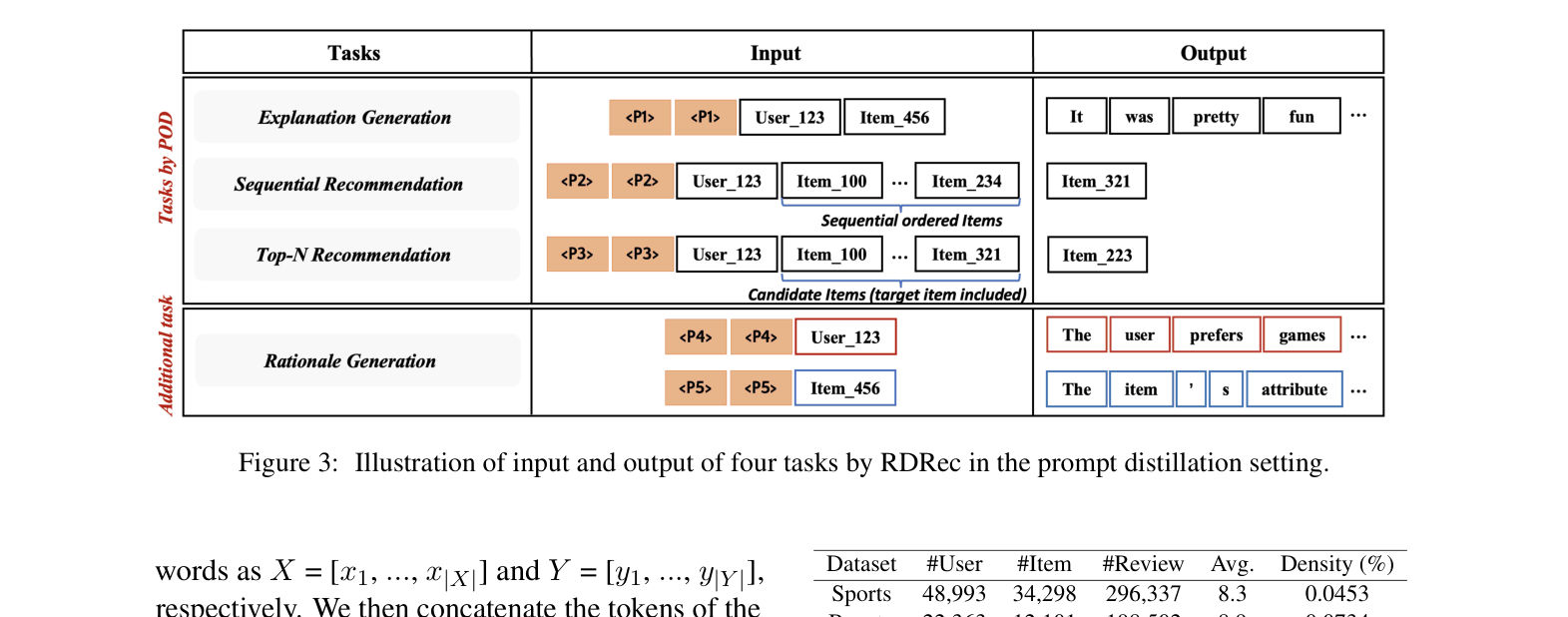
The input and output format for the T5-based RDRec model across four tasks (Sequential Rec, Top-N Rec, Explanation, Rationale Generation).
Evaluation Highlights
- Achieves up to +42.2% improvement in Top-N recommendation accuracy (Hit Rate@1) on the Beauty dataset compared to the SOTA baseline POD.
- Consistently outperforms baselines (P5, POD, RSL) across three Amazon datasets (Sports, Beauty, Toys) in both Sequential and Top-N tasks.
- Demonstrates that training on distilled rationales allows a small model (T5-small) to effectively reason about user preferences better than models trained on raw text.
Breakthrough Assessment
7/10
Significant performance gains, especially in Top-N tasks, by addressing the specific problem of noise in textual reviews. The method is a logical but effective extension of the P5/POD paradigm using knowledge distillation.