📊 Experiments & Results
Evaluation Setup
Top-K Recommendation (ranking 20 candidates) and Interaction Prediction (binary classification)
Benchmarks:
- MovieLens-1M (Movie Recommendation)
- Amazon-Grocery (E-commerce Recommendation)
- Amazon-Health (E-commerce Recommendation)
Metrics:
- Hit Rate @ 1 (HR@1)
- Hit Rate @ 2 (HR@2)
- Precision
- Recall
- F1 Score
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| BDLM outperforms both traditional domain models and LLM-based baselines on Top-K recommendation tasks across all datasets. | ||||
| MovieLens-1M | HR@1 | 0.372 | 0.460 | +0.088 |
| Amazon-Grocery | HR@1 | 0.339 | 0.440 | +0.101 |
| Amazon-Health | HR@1 | 0.344 | 0.403 | +0.059 |
| Ablation studies show that initialization from domain models and joint learning are both critical. | ||||
| MovieLens-1M | HR@1 | 0.360 | 0.431 | +0.071 |
Experiment Figures
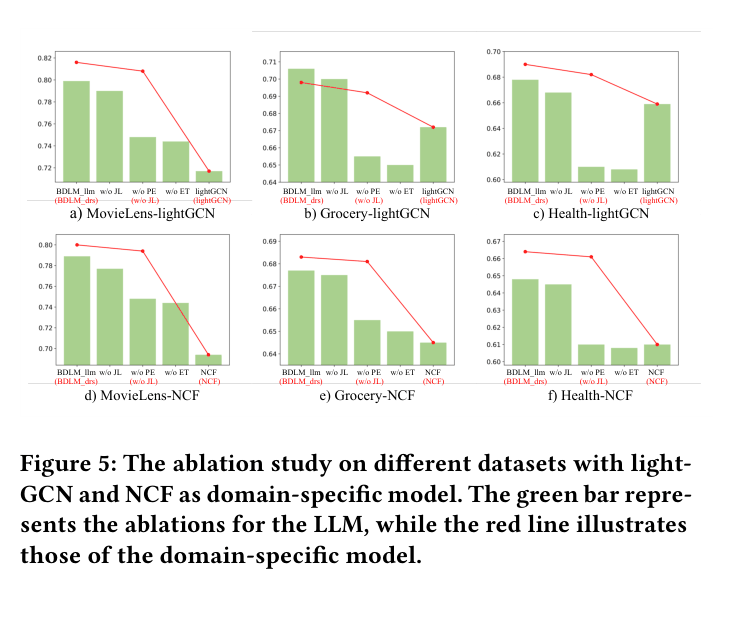
Ablation study bar charts across three datasets
Main Takeaways
- Text-only LLMs (InstructRec) perform well on movies but poorly on e-commerce (Grocery/Health) because product descriptions are less discriminative than movie titles; BDLM fixes this via ID embeddings.
- The domain-specific model (BDLM-drs) generally outperforms the LLM side (BDLM-llm) in the final inference, benefitting from the semantic knowledge injected during joint training.
- Mutual learning provides significant gains over static pre-loading of embeddings, proving the dynamic alignment loop is effective.
- Generalization: BDLM works with different backbone domain models (LightGCN and NCF), consistently improving over the base versions.