📊 Experiments & Results
Evaluation Setup
Offline evaluation using historical datasets where user choices/ratings are known
Benchmarks:
- Amazon-Electronics (Task 1: Unordered Sequence Selection)
- MovieLens 1M (Task 1: Unordered Sequence Selection)
- Spotify Million Playlist (Task 2 & 3: Sequence Ordering & Slate Recommendation)
- MIND (Microsoft News) (Task 2 & 3: Sequence Ordering & Slate Recommendation)
Metrics:
- Empirical Regret (utility loss between user-preferred and model-preferred slates)
- Transitivity (coherence metric)
- Asymmetry (coherence metric)
- Rating Transitivity (consistency with scalar ratings)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Task 1 (Amazon/MovieLens) | Empirical Regret | Qualitatively higher regret | Qualitatively lower regret | Positive correlation |
| Performance on Task 3 (Slate Recommendation) shows LLMs significantly outperforming random baselines across coherence metrics. | ||||
| MIND (Task 3) | Transitivity | 0.75 | 0.95 | +0.20 |
| Spotify (Task 3) | Transitivity | 0.75 | 0.98 | +0.23 |
Experiment Figures
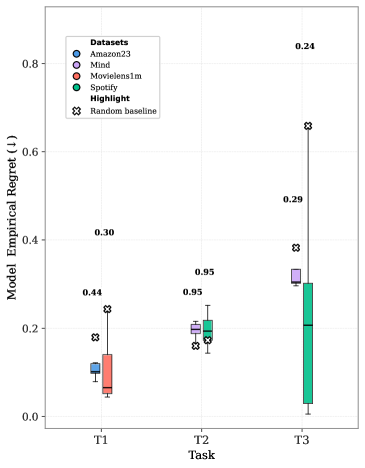
Distribution of Empirical Regret across models and tasks, compared with average slate similarity.
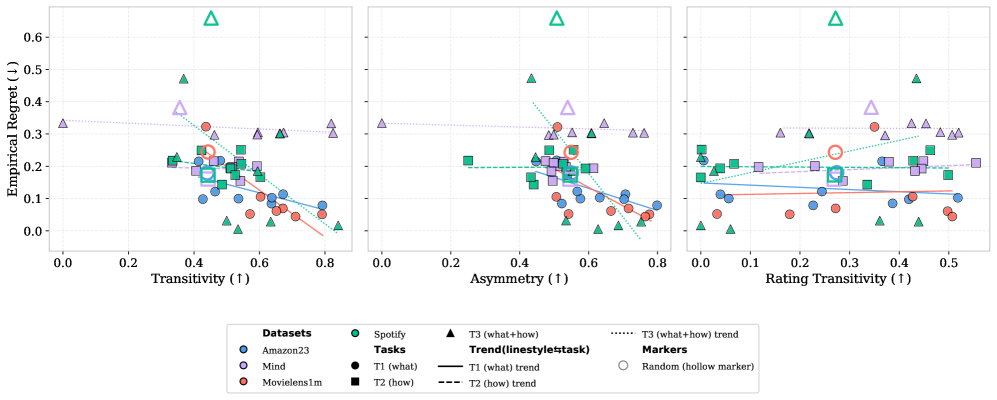
Scatter plots correlating Empirical Regret (y-axis) with Coherence Metrics (x-axis: Transitivity, Asymmetry).
Main Takeaways
- Task Difficulty: Unordered selection (Task 1) and full slate recommendation (Task 3) are handled well by LLMs because slates are semantically distinct (lower similarity).
- Ordering Difficulty: Pure re-ranking (Task 2) is very hard for LLMs; when slates differ only by order (high similarity), models struggle to beat random baselines or maintain coherence.
- Coherence is a Proxy for Quality: There is a strong inverse relationship between internal logical consistency (transitivity) and regret, suggesting that 'rational' LLMs are better user simulators.
- Paradox of Task 3: While conceptually hardest (selection + ordering), it is easier for LLMs than Task 2 because the candidate slates usually have different item compositions, making the preference signal stronger.