📝 Paper Summary
LLM-based Recommendation
Generative Flow Networks (GFlowNets)
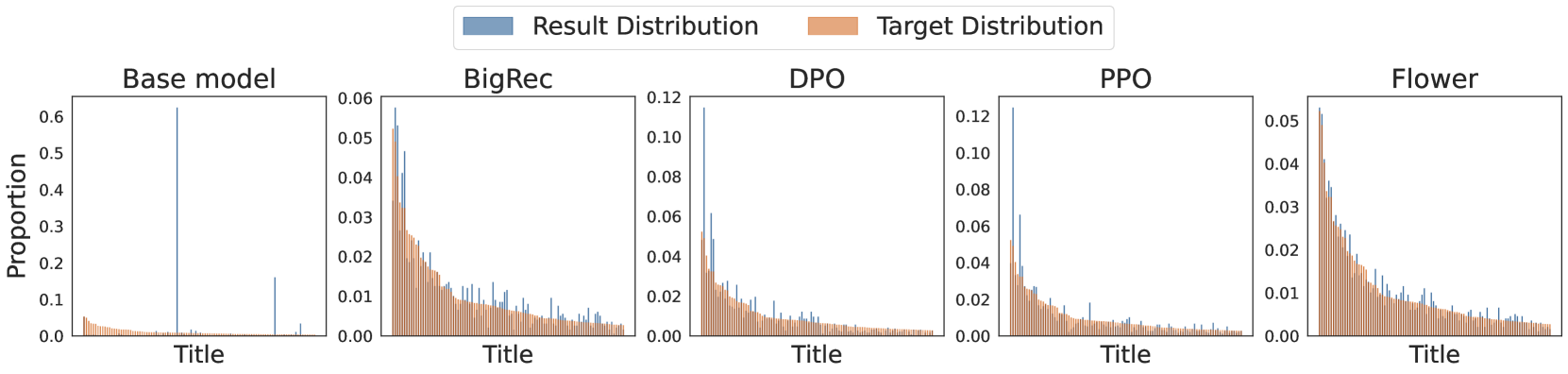
Flower replaces standard fine-tuning with a GFlowNet-based approach that aligns token generation probabilities with item rewards step-by-step, effectively mitigating popularity bias and improving diversity.
Core Problem
Supervised Fine-Tuning (SFT) in recommenders maximizes likelihood, which overfits to dominant patterns, causing severe popularity bias and lack of diversity in generated items.
Why it matters:
- Recommender systems that only suggest popular items (e.g., 'Harry Potter') fail to uncover niche user interests, degrading user experience.
- Post-hoc fixes like RLHF or DPO often lead to 'distribution collapse,' where the model converges to a single high-reward output rather than maintaining a diverse, valid distribution.
- Current bias mitigation strategies (re-weighting samples) fail to fundamentally align the model's generation process with the true target distribution.
Concrete Example:
In a movie recommendation task, an SFT-trained model given the prompt 'Recommend a movie' might overwhelmingly generate 'Back to the Future' because it appears most often in training, ignoring less popular but valid options like 'Back to School', even if the user prefers niche comedies.
Key Novelty
Flow-guided Fine-tuning Recommender (Flower)
- Conceptualizes the set of all item titles as a prefix tree where generation is a flow from root to leaf, rather than just independent classifications.
- Decomposes item-level rewards (like popularity or user preference) into token-level 'flow' values, ensuring the probability of picking a token is exactly proportional to the rewards accessible through it.
- Uses heuristic rewards (frequency counts or auxiliary model scores) to provide dense, step-by-step supervision without needing to train a complex separate reward model.
Architecture
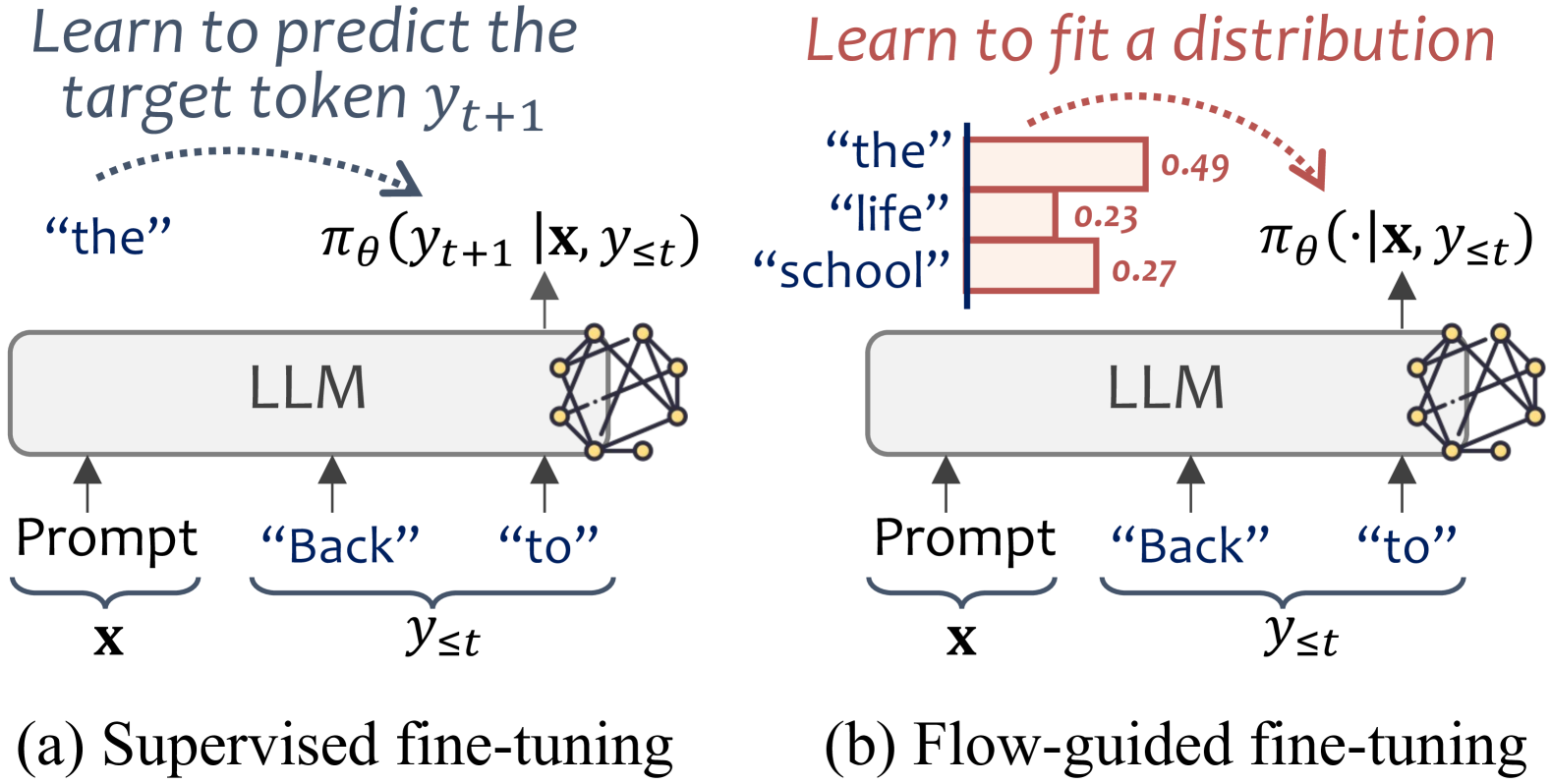
Contrast between SFT and Flower (GFlowNet) fine-tuning paradigms.
Evaluation Highlights
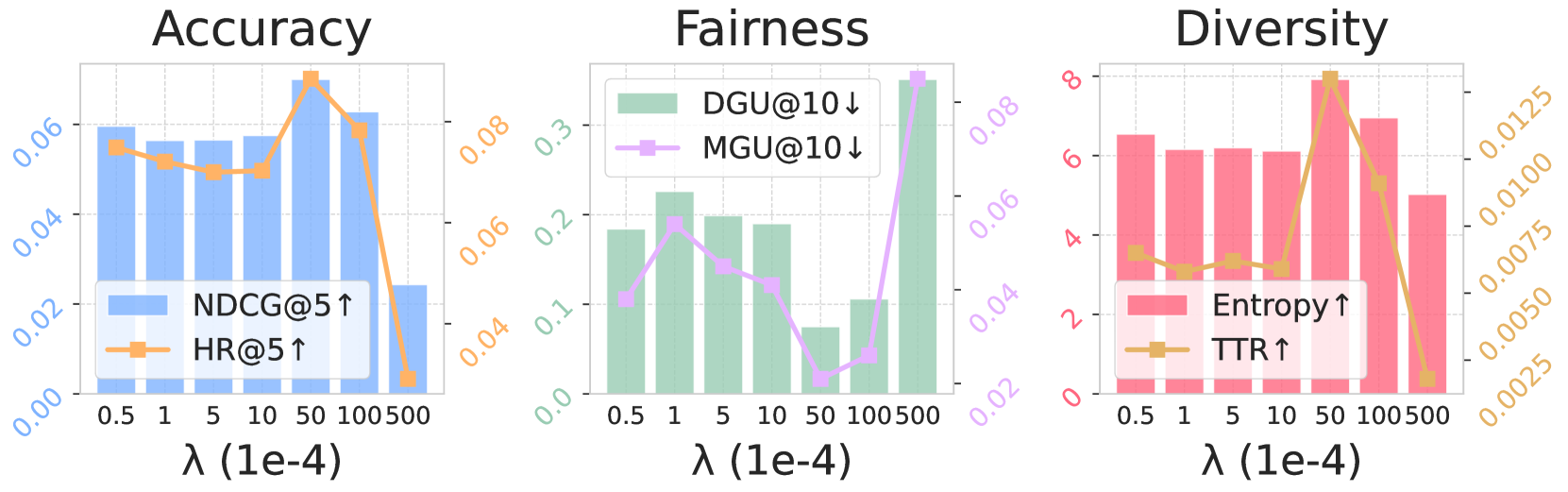
- Reduces popularity bias (DGU metric) by ~73% compared to standard SFT (BIGRec) on the Video Games dataset (0.052 vs 0.198).
- Improves distribution fitting significantly: reduces KL divergence from 2.193 (SFT) to 0.246 (Flower) on the Movies dataset target distribution.
- Increases recommendation diversity (Entropy) from 7.828 (SFT) to 8.428 (Flower) on Video Games while maintaining comparable accuracy.
Breakthrough Assessment
8/10
Offers a mathematically grounded alternative to SFT for generative recommendation that inherently solves diversity/bias issues via GFlowNets, rather than patching them post-hoc.